시리즈
- 1주차: 대회 이해하기
- 2주차: Action Space 이해하기
- 3-4주차: Observation Space 이해하기
- 5주차: Reward 이해하기
- 6-8주차: 강화학습 실전 기술
최근 동향
osim-rl의 프로젝트 리더를 맏고 있는 Łukasz Kidziński 가 8월 7일에 Robust control strategies for musculoskeletal models using deep reinforcement learning 라는 제목의 webinar를 발표했다. 이 발표를 놓쳤다면, 아래의 녹화물을 확인하자.
리더보드
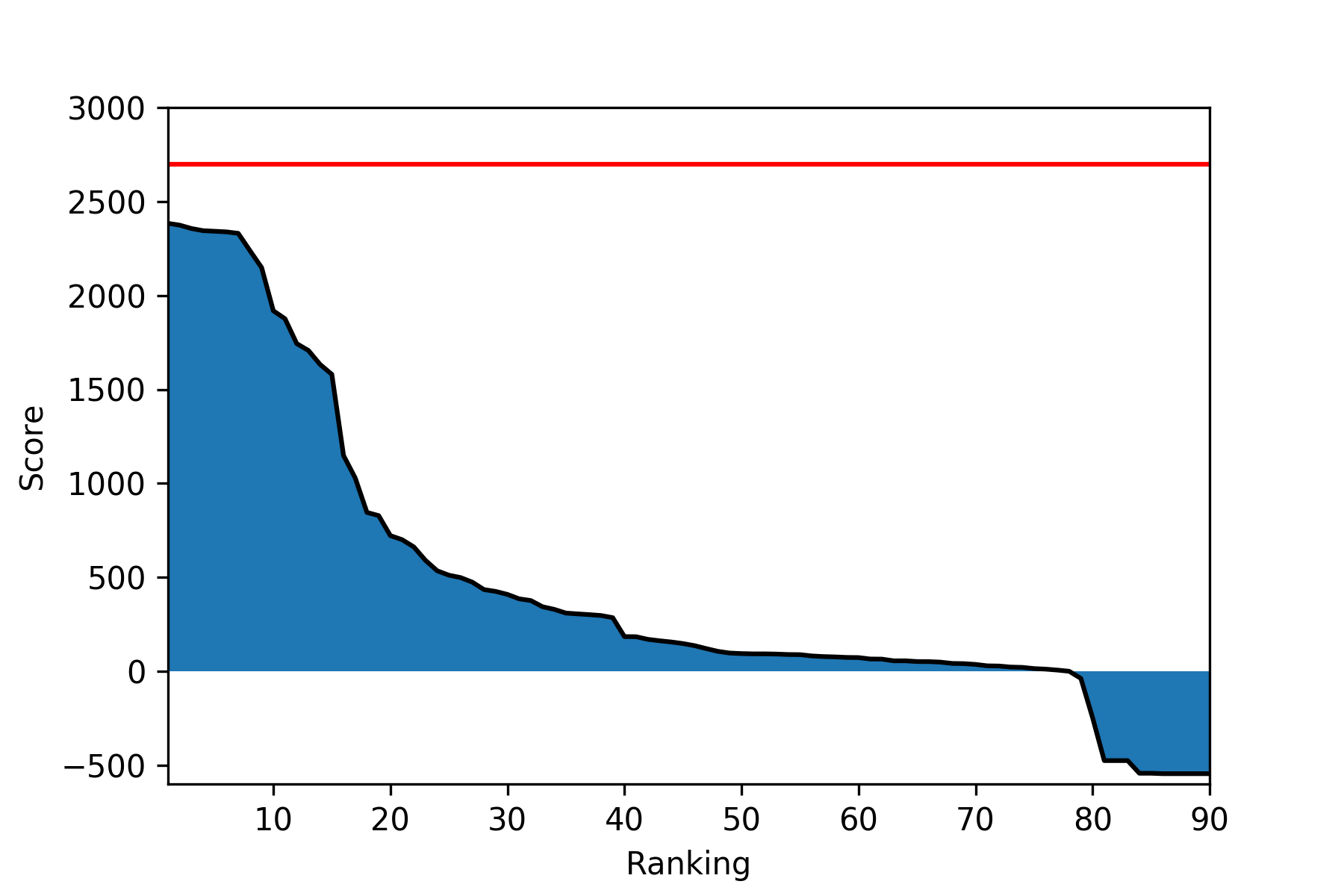
이번 주에는 최상위 10명에 3명의 새로운 사람들이 등장했고 (jbr, qyz55, jssk), 9개의 에이전트가 8월에 제출되었다.
| Participant | Cumulative Reward | Last Submission (UTC) |
|---|---|---|
| jbr | 2387.517 | Tue, 7 Aug 2018 21:44 |
| Firework | 2374.061 | Fri, 3 Aug 2018 04:49 |
| lijun | 2356.148 | Mon, 6 Aug 2018 10:16 |
| qyz55 | 2344.622 | Sun, 12 Aug 2018 07:32 |
| nskiran | 2341.482 | Tue, 31 Jul 2018 14:03 |
| jack@NAN | 2338.136 | Fri, 10 Aug 2018 05:15 |
| rl_agent | 2330.393 | Tue, 7 Aug 2018 17:54 |
| ymmoy999 | 2238.523 | Mon, 6 Aug 2018 14:02 |
| Yongjin | 2148.157 | Thu, 9 Aug 2018 22:54 |
| jssk | 1918.556 | Fri, 10 Aug 2018 06:06 |
또 36명의 새로운 참가자가 에이전트를 제출했고, 대부분이 0점을 넘어서 Google Cloud Platform 크레딧을 받을 최소자격을 갖추었다.
실전 기술
이번 주에는 대회에서 조금 벗어나서, 강화학습 연구 등에서 많이 쓰이는 실전 기술에 대해서 알아보도록 하자.
Frame Skipping
Frame skipping 은 같은 행동을 $k$개의 프레임동안 반복하는 방법이다. Playing Atari with Deep Reinforcement Learning 논문에서 처음 등장한 이 방법은 에이전트가 행동을 고르는 빈도수를 $\frac{1}{k}$ 로 낮추어서 에이전트가 같은 시간에 더 많은 경험을 할 수 있게 한다.
Discretized Actions
이 대회의 ProstheticsEnv 환경에서 action은 continuous하고, 대부분의 참가자가 쓰는 Policy Gradient 방식은 continuous action을 지원한다. 하지만, 많은 실사례에서 행동을 discretize(이산화) 하는 것이 더 뛰어난 성능을 보이므로, 행동을 discretize하는 것 또한 성능을 향상시킬 수 있을 것이다. 예를 들어, 가장 극단적인 discretization은 각 근육에 가하는 힘을 0과 1로 제한하는 것이다.
최근에 OpenAI에서 PPO를 써서 로봇 손으로 작은 블럭을 회전시키는 Learning Dexterous In-Hand Manipulation 논문을 발표하였는데, 이 논문 역시 action space가 continuous함에도 불구하고 action discretization을 했는데, 그 이유에 대해서는 아래와 같이 설명하였다.
While PPO can handle both continuous and discrete action spaces, we noticed that discrete action spaces work much better. This may be because a discrete probability distribution is more expressive than a multivariate Gaussian or because discretization of actions makes learning a good advantage function potentially simpler. We discretize each action coordinate into 11 bins.
Distributed Learning
만약 자원이 충분하다면, 성능을 올리기에 가장 뛰어난 방법은 병렬 연산일 것이다. 여러 개의 CPU와 GPU가 있다면, 병렬 연산은 에이전트가 몇 배에서 몇백 배까지의 경험을 쌓을 수 있다.
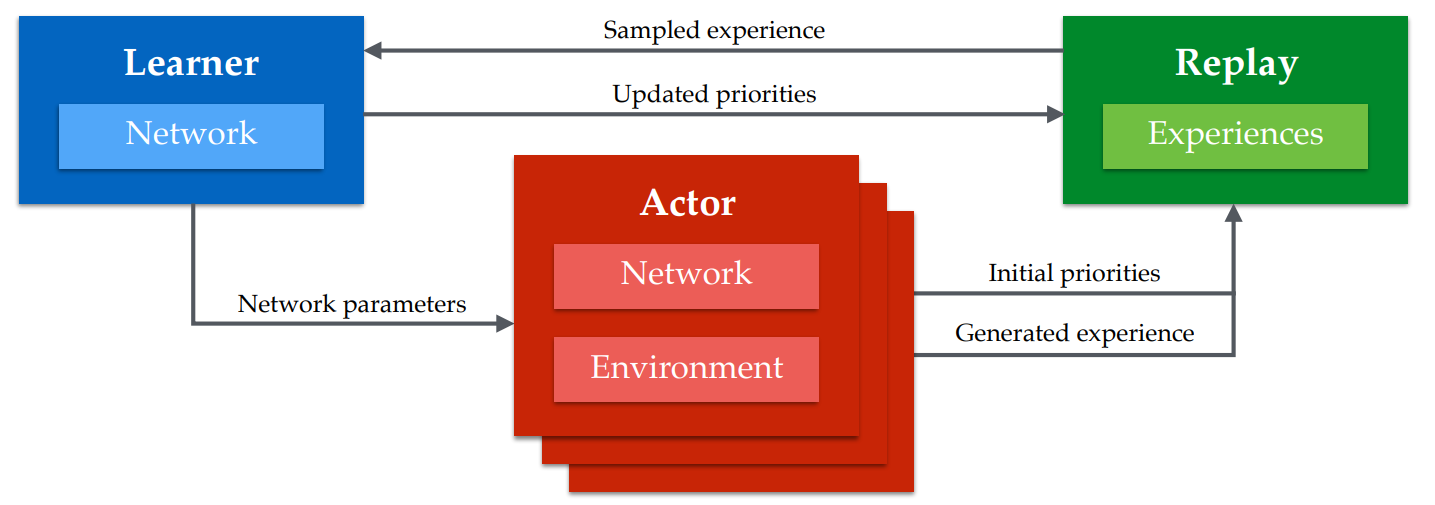
현재 강화학습의 여러 환경에서 최고의 성능을 뽐내고 있는 결과들은 대부분 병렬 연산을 활용한다. 구글 딥마인드의 Distributed Prioritized Experience Replay 의 Ape-X DQN 은 376 개의 CPU 코어와 GPU 1개를 사용해서 Rainbow 보다 200배의 속도로 경험을 쌓을 수 있었고, 덕분에 대부분의 Atari 2600 게임에서 병렬연산을 사용하지 않은 다른 방법보다 압도적으로 좋은 성적을 거두었다.
마찬가지로, 며칠 전에 도타2라는 게임에서 프로게이머들을 이긴 OpenAI Five 역시 128000개의 CPU 코어와 256개의 P100 GPU를 이용하여 하루에 자그마치 900년의 경험을 쌓을 수 있었다.
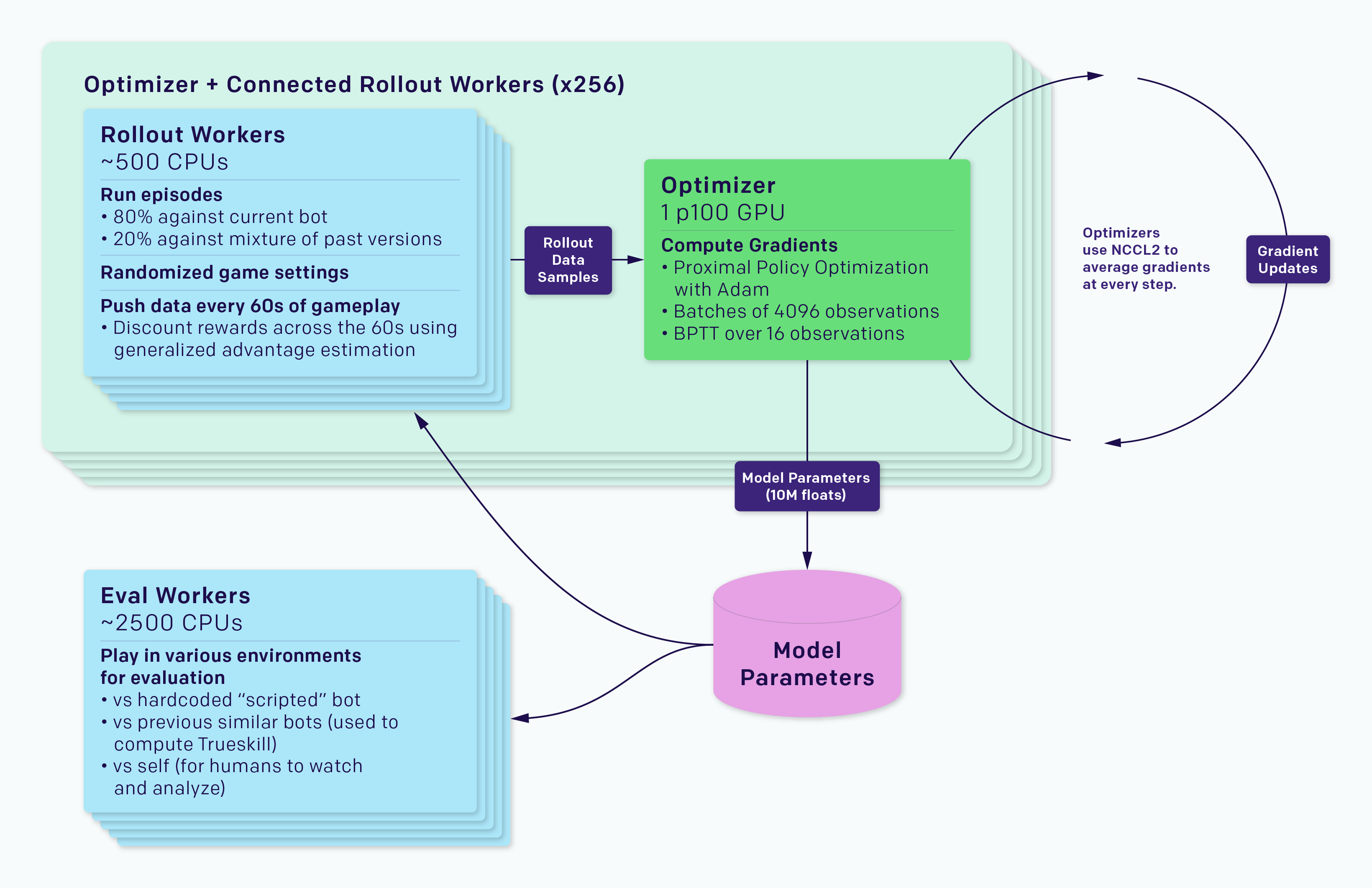
만약 병렬 연산에 관심이 있다면, Ray’s RLLib, Reinforce.io’s Tensorforce, 또는 OpenAI’s Baselines 을 확인해 보는 것을 추천한다.
대회에 적용해볼 만한 다른 방법을 더 찾고 싶다면, 작년 NIPS 2017 Learning to Run 대회 수상자들의 코드를 살펴보자!
다음 주 예정
이 대회에서는 DDPG나 PPO 같은 Policy Gradient 방식이 더 자연스럽지만, 개인적으로는 DQN부터 적용해보고 싶다. DQN 코드를 처음부터 다시 짜는 것은 너무 오래 걸려서 이미 구현된 코드를 쓸텐데, 어느 것을 쓸지 확실히 정하지는 않았지만, 아마 unixpickle의 anyrl-py 나 Kaixhin의 Rainbow 가 될 거라 생각한다.
또 Google Cloud Platform (GCP) 를 쓴 적이 없는데, 이제 배울 이유가 두 가지나 있으니 (AI for Prosthetics 대회, $250 크레딧) GCP를 세팅하는 방법도 배울 생각이다.