시리즈
- 1주차: 대회 이해하기
- 2주차: Action Space 이해하기
- 3-4주차: Observation Space 이해하기
- 5주차: Reward 이해하기
- 6-8주차: 강화학습 실전 기술
배경
AI for Prosthetics 대회는 2018년 NIPS 대회 중 하나로, 의족이 달린 3D 모델을 뛰게 하는 에이전트를 개발해는 것이 참가자들의 목적이다.
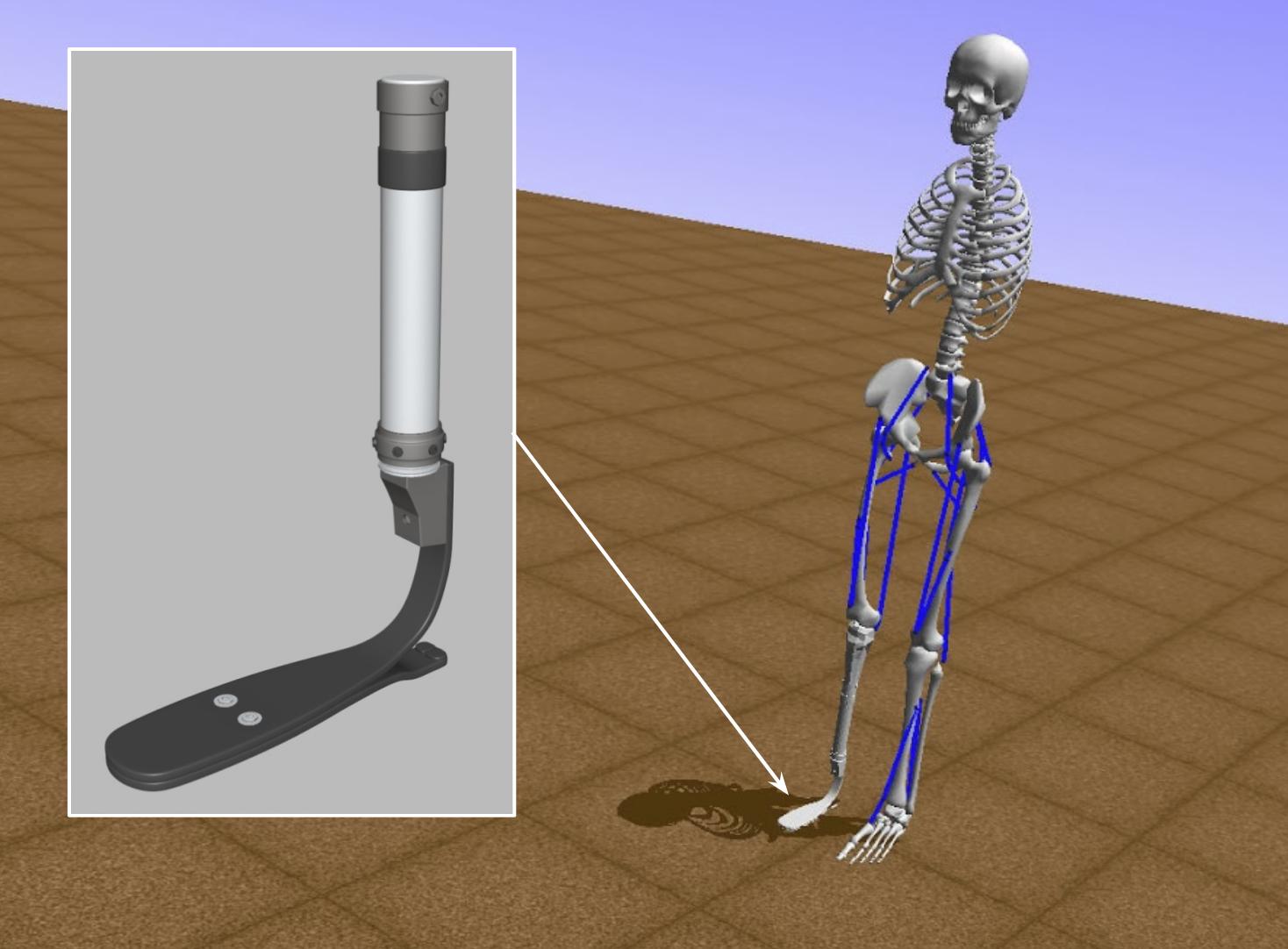
이 대회는 2017년에 열렸던 Learning to Run 대회의 연장선상에 있으며. 작년 대회에서부터 크게 세 가지가 발전되었다:
- 실험 데이터 사용을 허가했다
- 환경이 x, y축의 평면 (2D)에서 x, y, z축의 공간 (3D)으로 바뀌어서 옆으로 넘어질 수 있다
- 모델에 의족을 추가해서 오른쪽 무릎 아래를 조정할 수 없다

설치
대회에 참가하기 위해서는 우선 Anaconda로 몇 가지 패키지를 설치해야 한다.
conda create -n opensim-rl -c kidzik opensim python=3.6.1
source activate opensim-rl # Windows의 경우 activate opensim-rl
conda install -c conda-forge lapack git
pip install git+https://github.com/stanfordnmbl/osim-rl.git
설치가 무사히 완료되었다면, opensim-rl이라는 Anaconda 환경이 추가되었고, 그 환경 안에 osim-rl 이라는 파이썬 패키지가 설치되었을 것이다.
설치가 무사히 진행되었는지 확인하기 위해 아래 커맨드를 돌려보자.
python3 -c "import osim"
아무런 출력이 없다면 설치가 정상적으로 된 것이다. 만약 오류가 출력된다면 대회 공식 FAQ를 참조하는 것을 추천한다.
환경
from osim.env import ProstheticEnv
env = ProstheticsEnv()
환경은 opensim 패키지에서 제공되며, 강화학습의 표준인 OpenAI Gym의 형태를 따르고 있다. 즉, 다른 Gym 환경들처럼 env.reset(), env.step(), env.observation_space, 그리고 env.action_space 를 통해 환경에 대한 유용한 정보를 확인할 수 있다.
에이전트를 개발하려면, 우선 에이전트의 입출력에 대해서 알아야 한다. 기본적으로 에이전트의 입력은 환경으로부터 받는 observation (관측) 이며, 출력은 에이전트가 선택한 action (행동) 이다.
Observation Space
print(env.observation_space) # Returns `Box(158,)`
Observation space 는 gym.spaces.Box 타입이다. 만약 Gym의 spaces에 익숙하시지 않다면, 단순히 158개의 숫자로 이루어져 있다고 생각해도 무리가 없다. (gym의 Box() 에 대해서는 OpenAI Gym 문서에 자세히 설명되어 있다.)
observation = env.reset(project=False)
observation, _, _, _ = env.step(action, project=False)
Observation을 더 자세히 알아보고 싶다면, env.reset()이나 env.step() 에 project=False 파라미터를 줄 수 있다. 기본적으로는 project=True 로 설정되어 있으며, 이 때 환경이 반환하는 observation은 길이 158짜리 list이다. 하지만 project=False 로 설정되어 있다면, 환경은 각각의 숫자를 설명하는 dictionary를 반환한다.
{ 'body_acc': { 'calcn_l': [ 1253.6888287987226,
453.41172562050133,
-462.8844724817433],
'femur_l': [ 3552.7596723666484,
102.32773696018944,
-24.145907744606134],
'femur_r': [ 3577.239291929728,
97.25560037366972,
-24.145907744606134],
...
Action Space
print(env.action_space) # Returns `Box(19,)`
print(env.action_space.low) # Returns list of 19 zeroes
print(env.action_space.high) # Returns list of 19 ones
print(env.action_space.sample()) # Returns a random action
이 환경의 Action space 역시 gym.spaces.Box 타입이다. 올바른 action 은 길이 19의 list 형태이며, 각각의 숫자가 0과 1 사이의 실수이어야 한다. 각각의 숫자는 그 근육에 어느 정도의 힘을 적용할지를 나타내므로, 0은 아예 힘을 주지 않는 것을 나타내고, 1은 최대한의 힘을 주는 것을 나타낸다.
osim-rl-helper
대회를 시작하는 사람들을 위해서 osim-rl-helper라는 간단한 GitHub repository를 만들었다. 대회를 막 참가하신 사람이라면 이 코드를 통해서 간단한 클라이언트의 작동방식이나 첫 에이전트를 제출하는 방법을 확인하는 것을 추천한다.
Agent
개인적으로 나는 대회에서 한 가지 아이디어를 선택하기 전에 여러 가지 아이디어를 실험하는 걸 좋아하고, 각각의 아이디어들이 어떤 결과를 내었는지 기록하는 것을 좋아한다. 그래서 여러 agent들을 체계적으로 관리하기 위해 Agent 라는 클래스를 만들었다. 물론, 알고리즘에 따라 에이전트의 역할은 바뀌기 때문에 많은 부분을 체계적으로 정리할 수는 없었다. 대신, 로컬 컴퓨터에서 에이전트를 실험하는 Agent.test() 와 에이전트를 서버와 연동시키는 Agent.submit() 를 구현하였다. (두 함수 모두 구현되지 않은Agent.act()를 바탕으로 하고 있다)
그런데, 에이전트를 서버와 연결해서 제출하려 할때, 두 가지 에러가 계속 나는 것을 발견했다.
client의env_id가ProstheticsEnv이어야 한다.client.env_step()은 NumPy 타입을 받지 않는다.
1번 실수는 Agent.submit()을 구현한 후에 없어졌지만, 2번 실수는 계속해서 했기 때문에, Agent.test()나 Agent.submit()이 실행되기 전에 Agent.sanity_check()라는 검사가 자동으로 실행되게 구현하였다.
def sanity_check(self):
"""
Check if the agent's actions are legal.
"""
observation = [0] * 158
action = self.act(observation)
if type(action) is not list:
return (True, 'Action should be a list: are you using NumPy?')
if not is_jsonable(action):
return (True, 'Action should be jsonable: are you using NumPy?')
return (False, '')
Baselines (베이스라인)
Agent 클래스를 제작한 후, 이 패키지를 쓸 분들의 이해를 돕기 위해 몇 가지 간단한 baseline agent를 만들었다. 첫 번째 에이전트는 osim-rl 대회의 공식 튜토리얼에도 있는 RandomAgent이다.
class RandomAgent(Agent):
def __init__(self, env):
self.env = env
def act(self, observation):
return self.env.action_space.sample().tolist()
또다른 간단한 agent는 언제나 같은 행동을 하는 FixedActionAgent 입니다.
class FixedActionAgent(Agent):
"""
An agent that choose one fixed action at every timestep.
"""
def __init__(self, env):
self.action = [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0]
def act(self, observation):
return self.action
대회가 진행되면서 새로운 baseline agent를 추가할 것이며, 만약 관심이 있다면 GitHub에서 watch나 star를 하면 바로 확인할 수 있다.
다음 주 예정
RandomAgent와 FixedActionAgent 둘 다 관측한 observation을 사용하지 않고 행동을 선택하므로, 강화학습 에이전트라고 부르기에는 무리가 있다. 다음 주는 환경이 주는 observation을 사용하는 간단한 에이전트를 만들어 보도록 하자.
또한, 다음 주와 다다음 주는 action space와 observation space를 좀 더 주의깊게 살펴 볼 것이다. Policy Gradient쪽 알고리즘을 구현해서 강화학습 에이전트를 만드는 것도 중요하지만, observation과 action에 대해 잘 안다면, feature engineering을 통해 에이전트가 더 빨리 학습할 수 있게 도울 수 있기 때문이다.