시리즈
- 1주차: 대회 이해하기
- 2주차: Action Space 이해하기
- 3-4주차: Observation Space 이해하기
- 5주차: Reward 이해하기
- 6-8주차: 강화학습 실전 기술
근육들
저번 주에, 하나의 행동이 0과 1 사이의 19개의 숫자로 이루어져 있고, 이 19개의 숫자는 각 근육에 어느 정도의 힘을 줄 것인지를 나타낸다는 것을 확인하였다. 근육이 어떤 방식으로 작동하는지 과학적인 이론을 토대로 추측하는 것보다, 각각의 근육에 힘을 주고 그것이 모델에 어떤 영향을 미치는지 알아보도록 하자.
Index 0
Index 1
Index 2
Index 3
Index 4
Index 5
Index 6
Index 7
Index 8
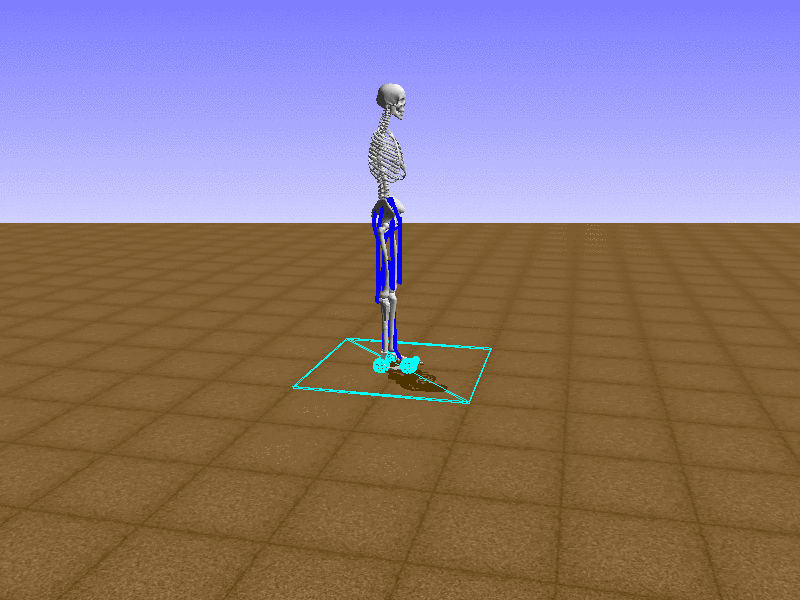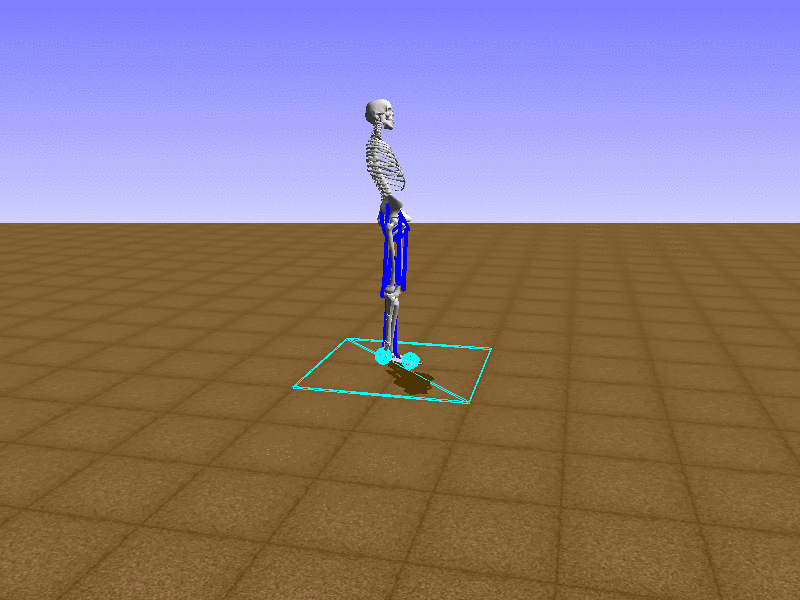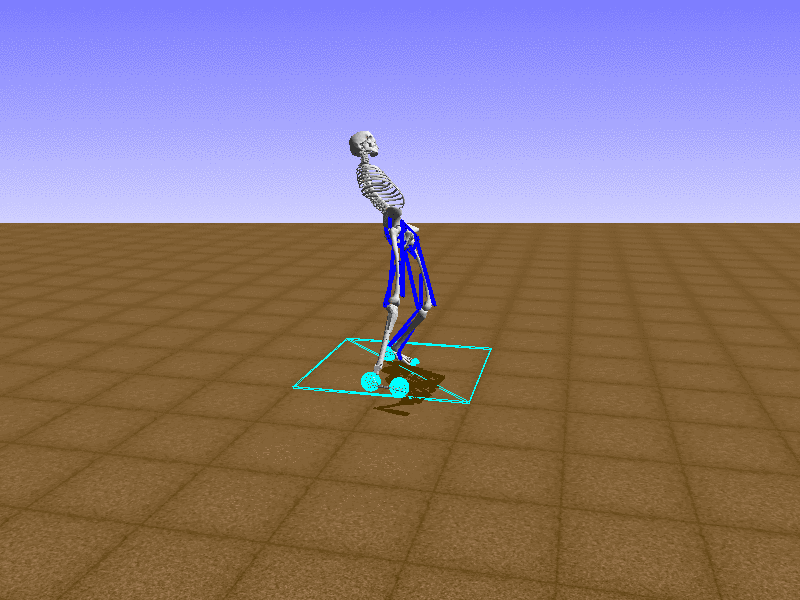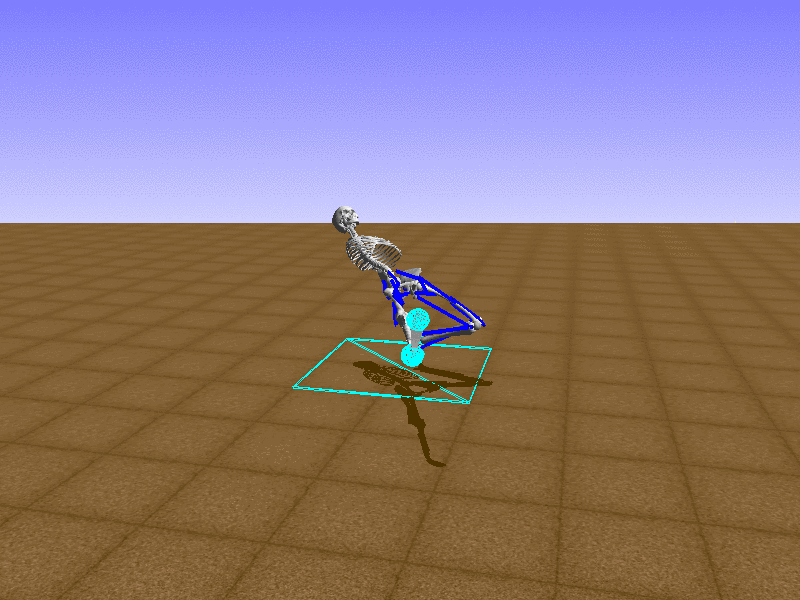
Index 9
Index 10
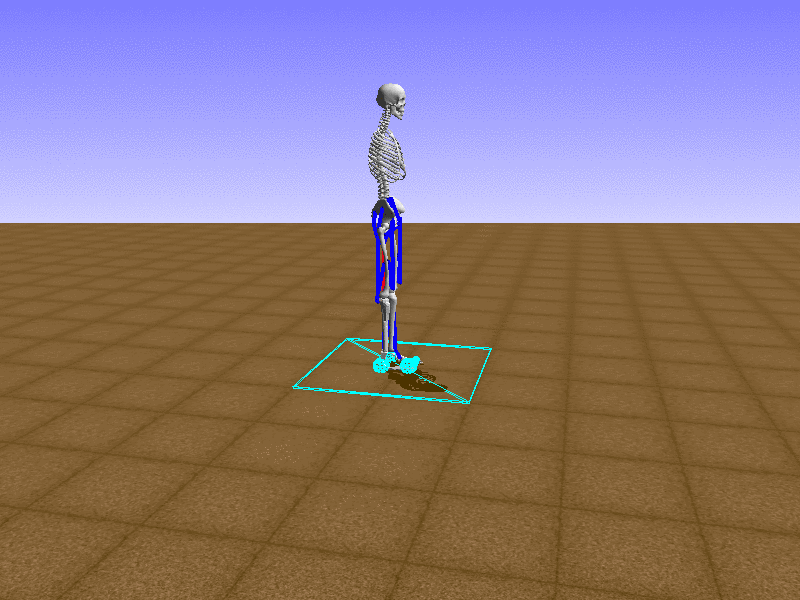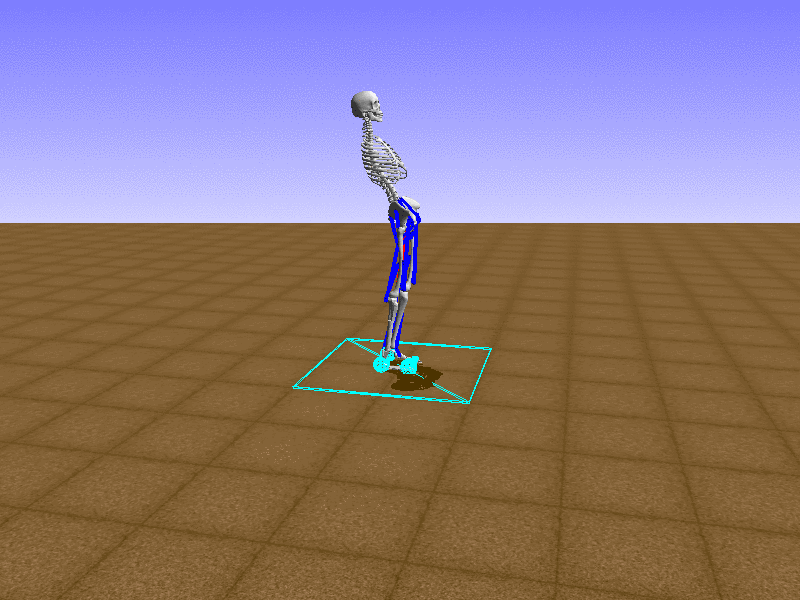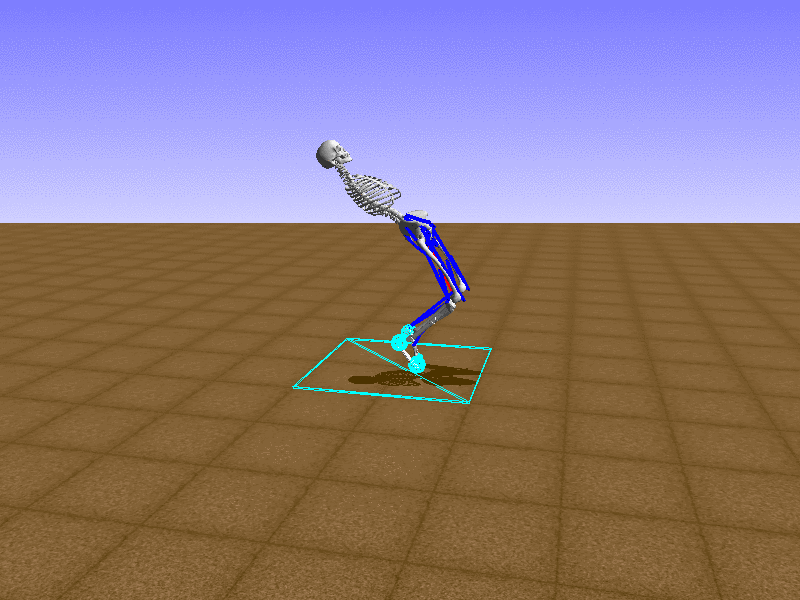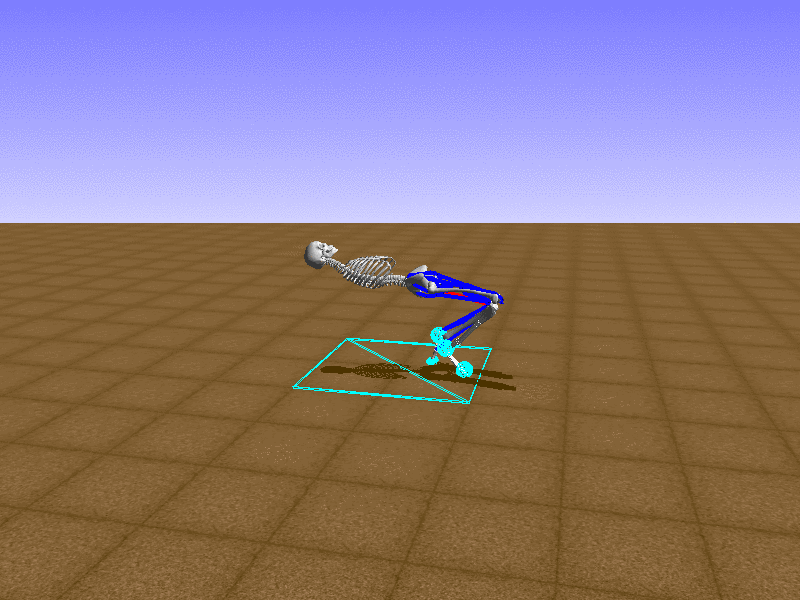
Index 11
Index 12
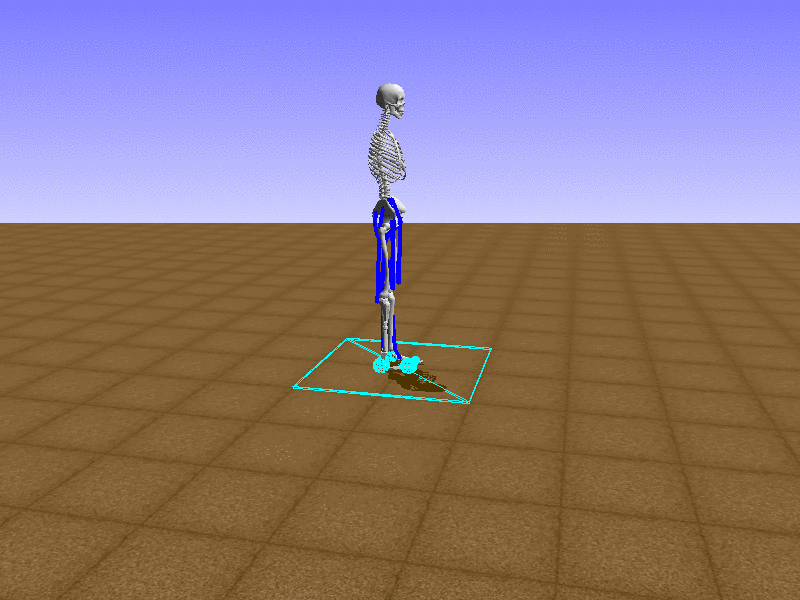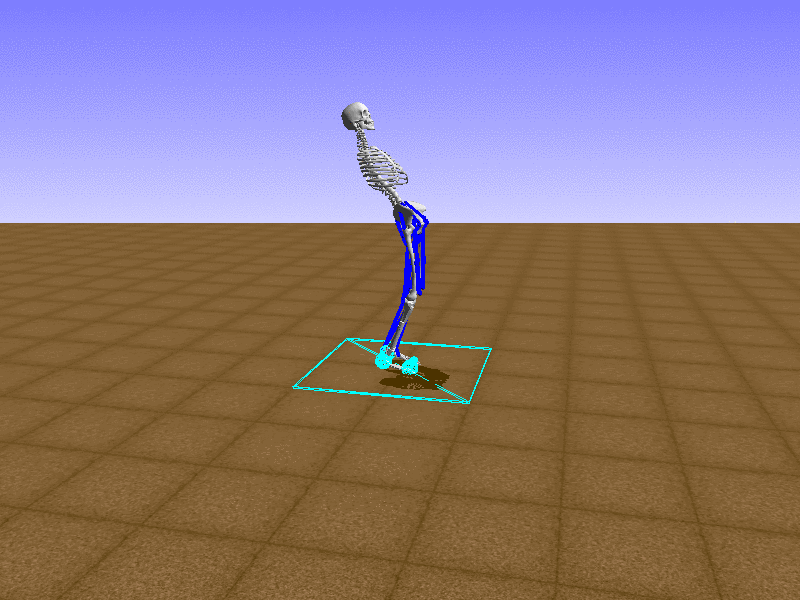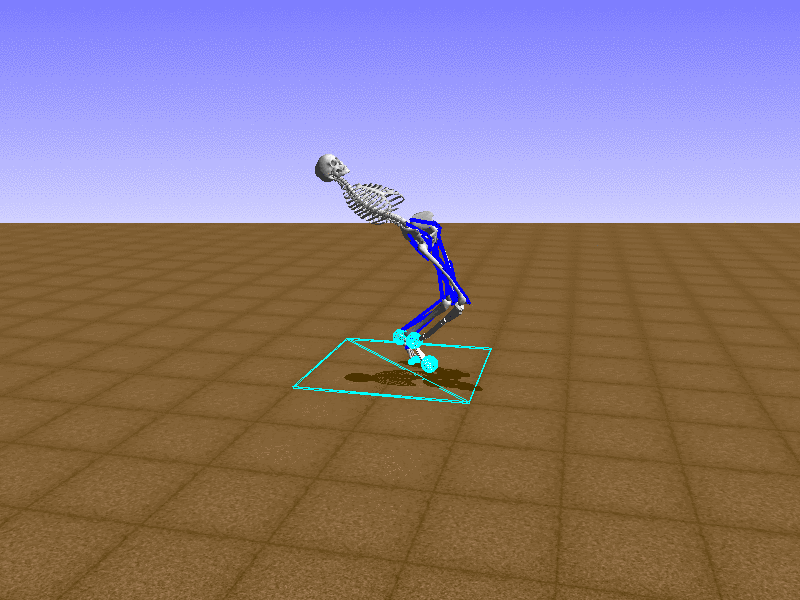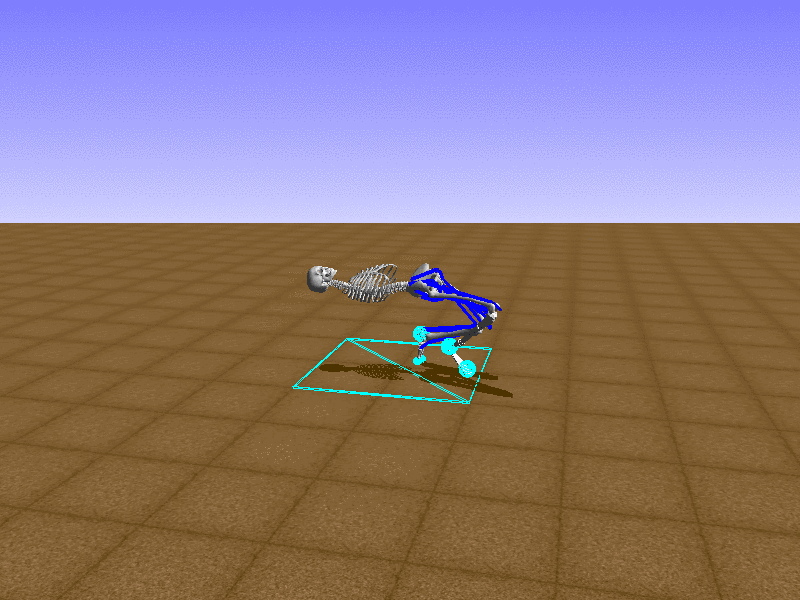
Index 13
Index 14
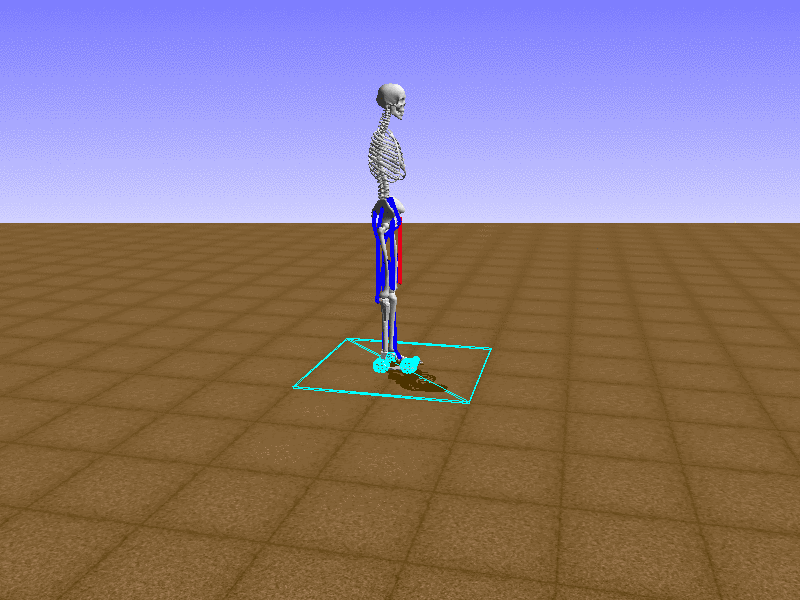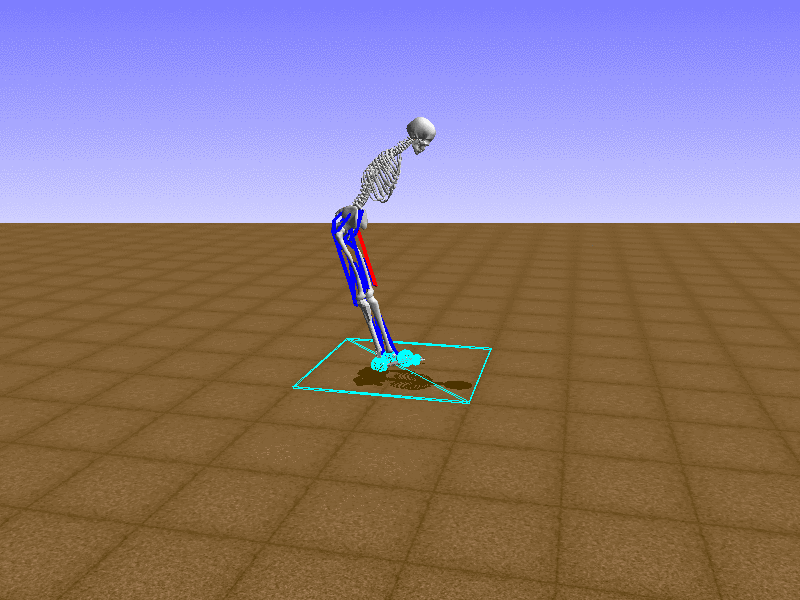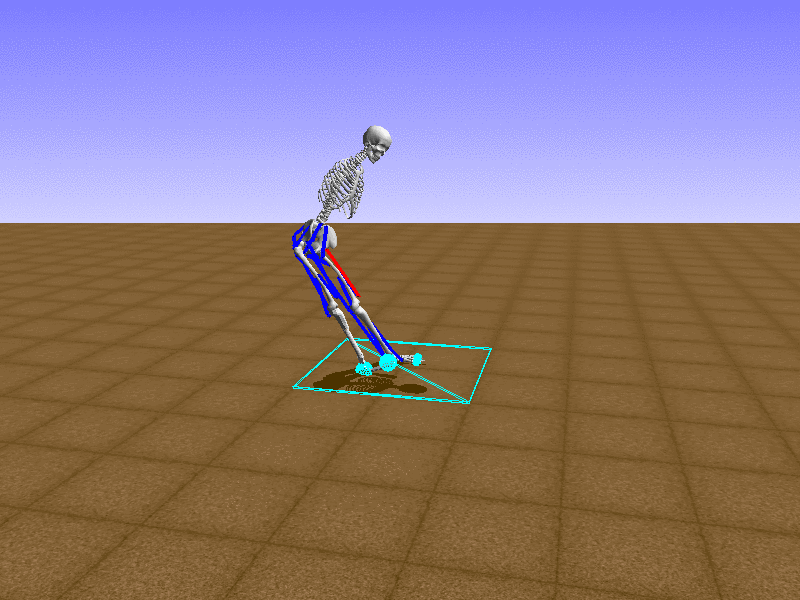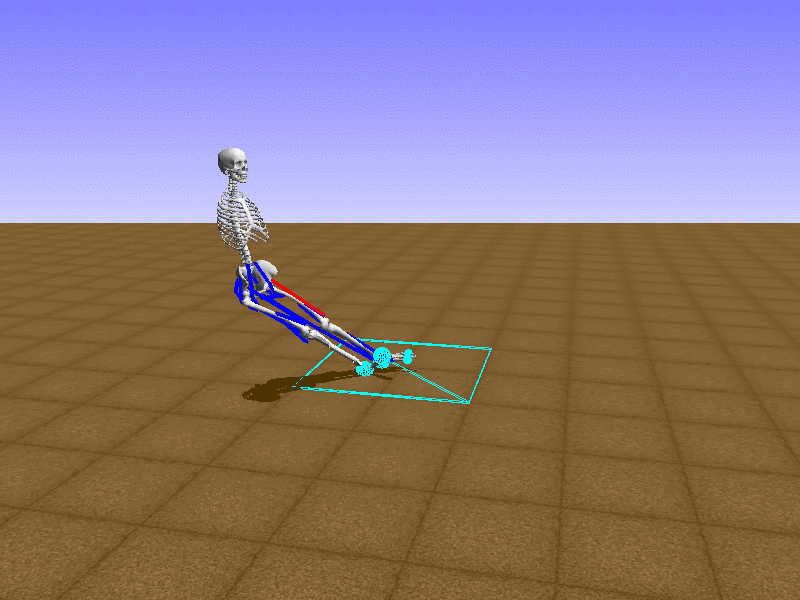
Index 15
Index 16
Index 17
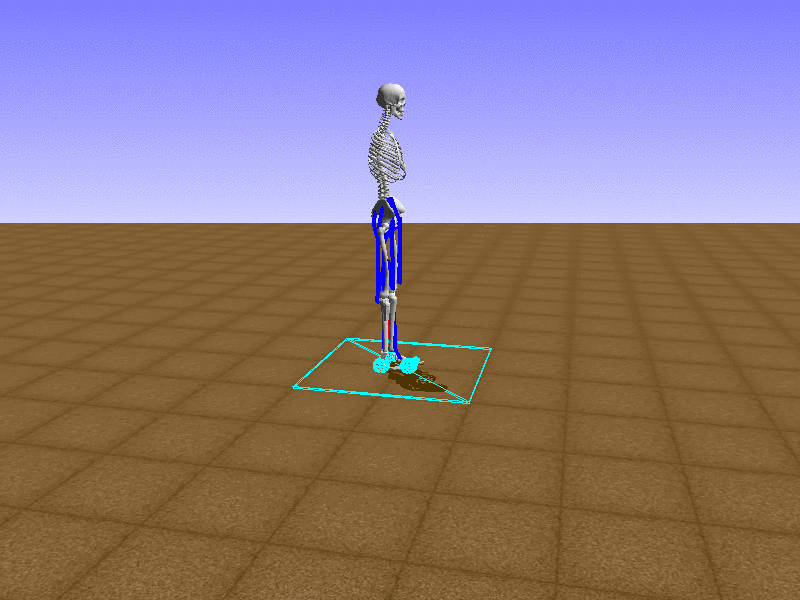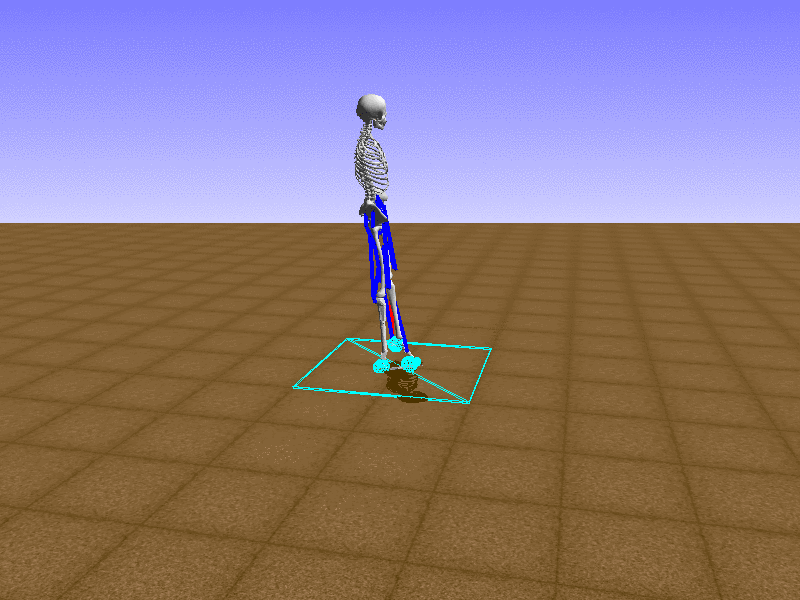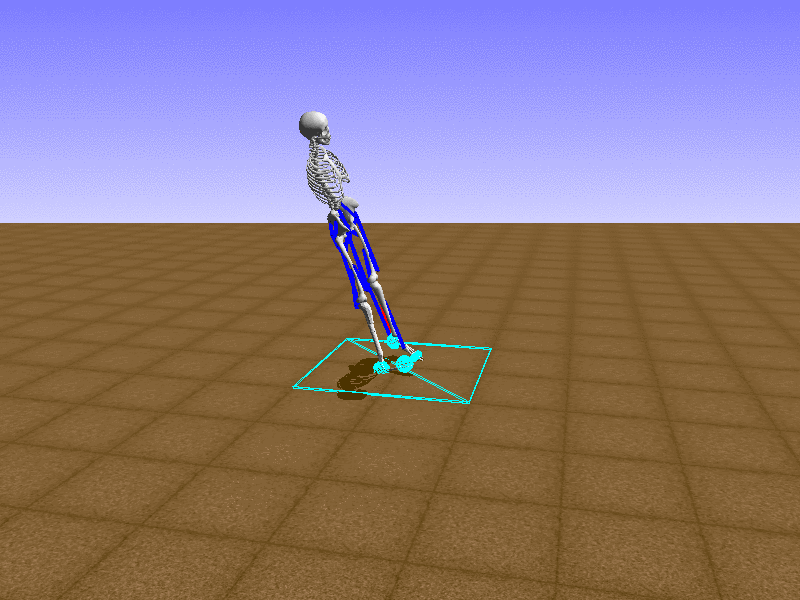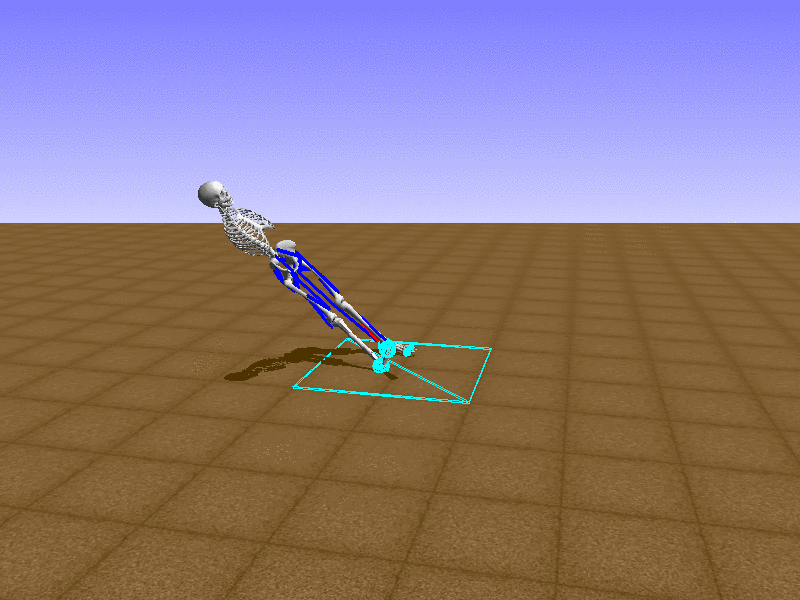
Index 18
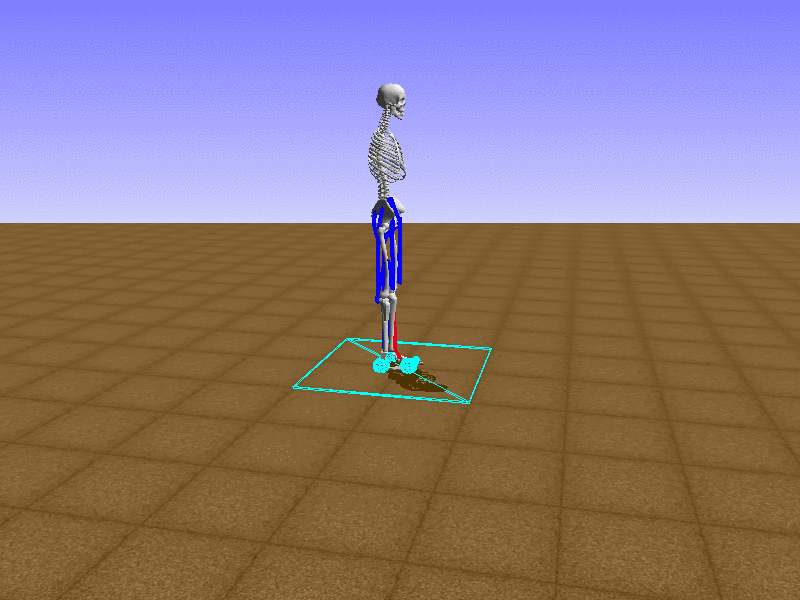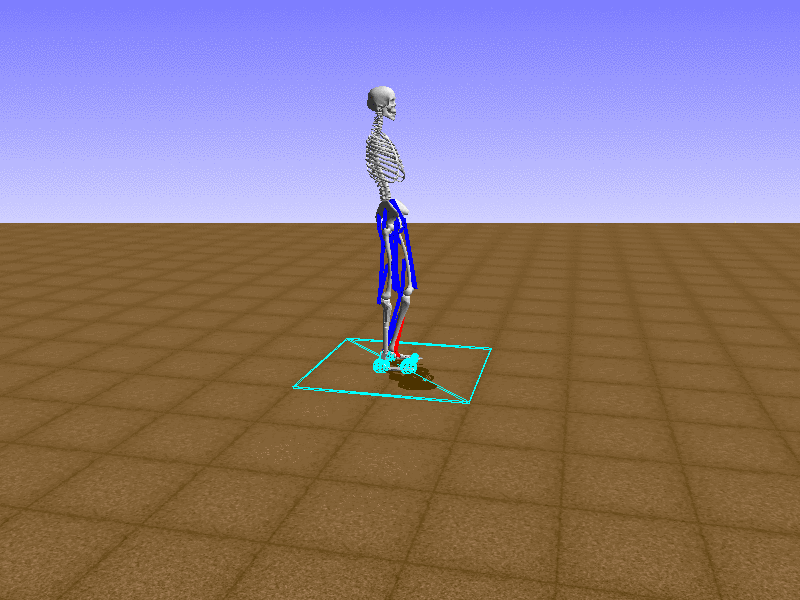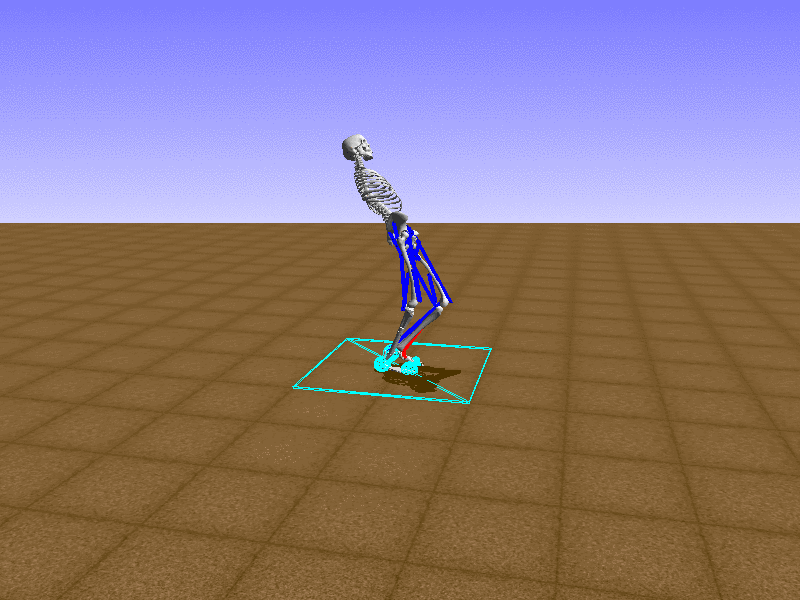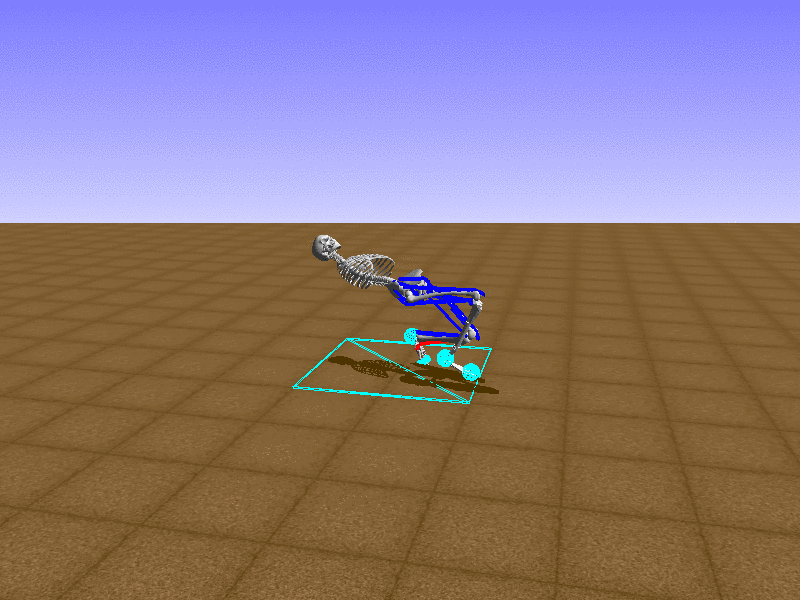
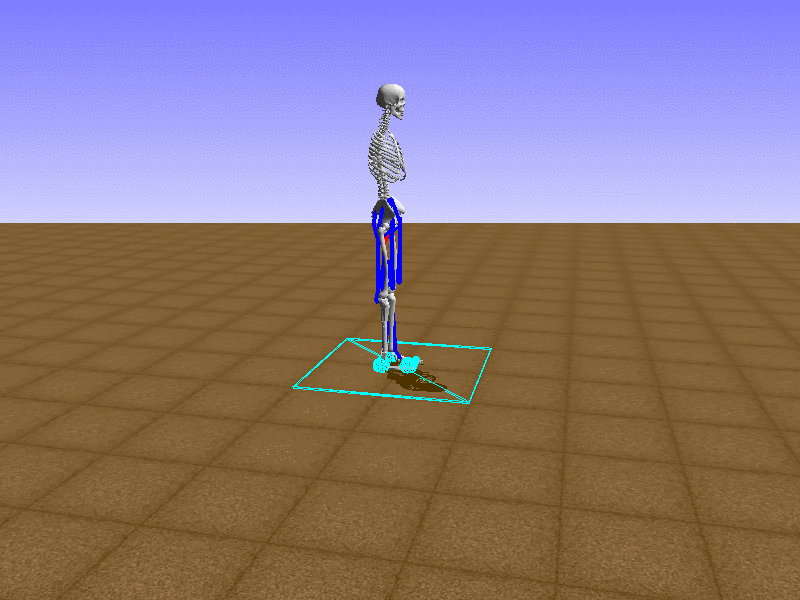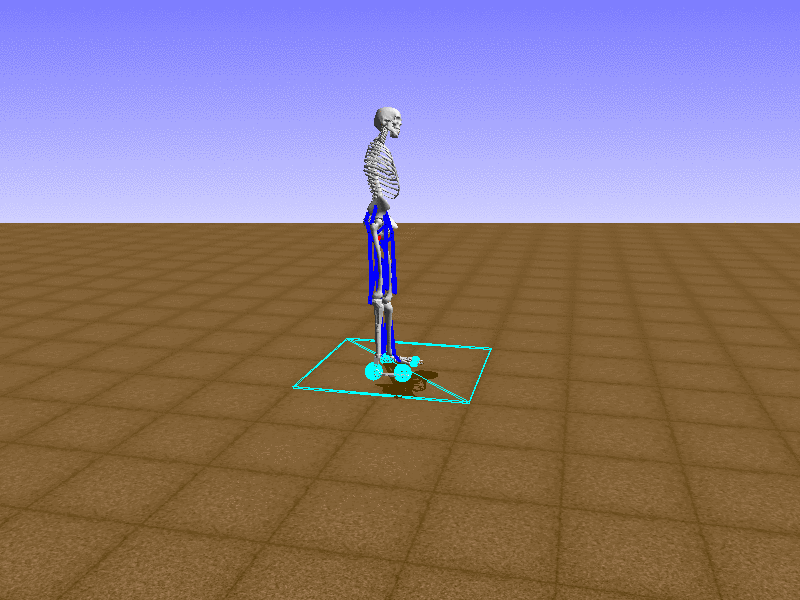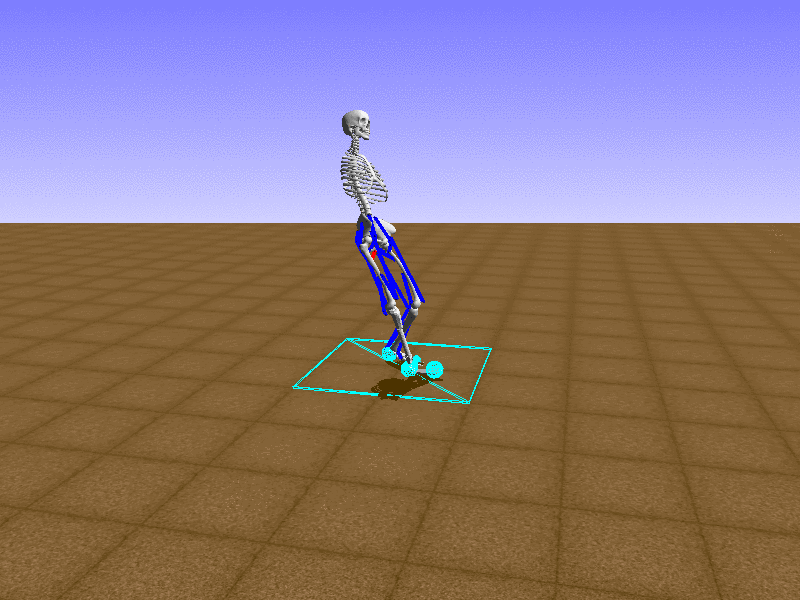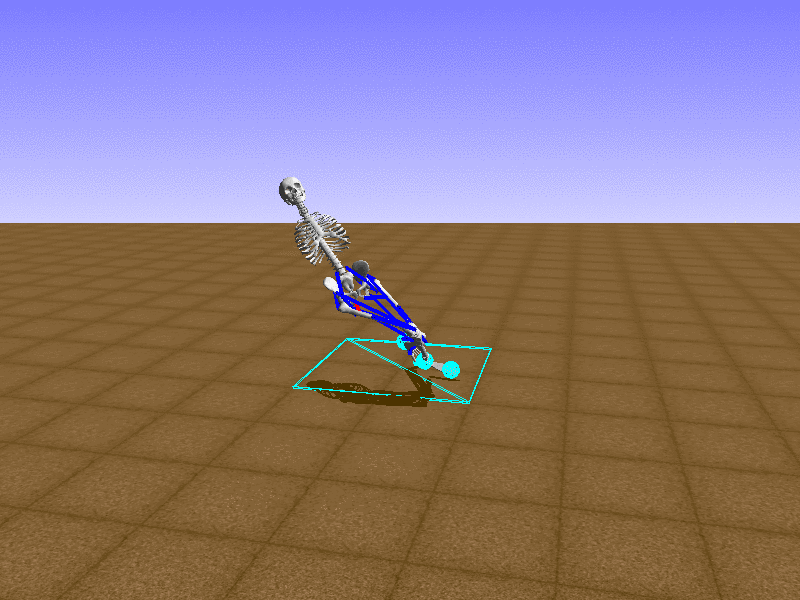
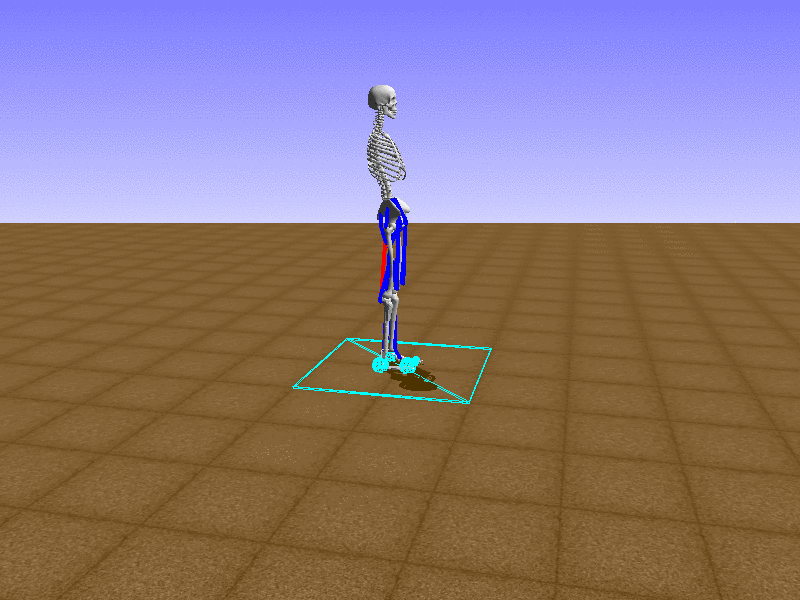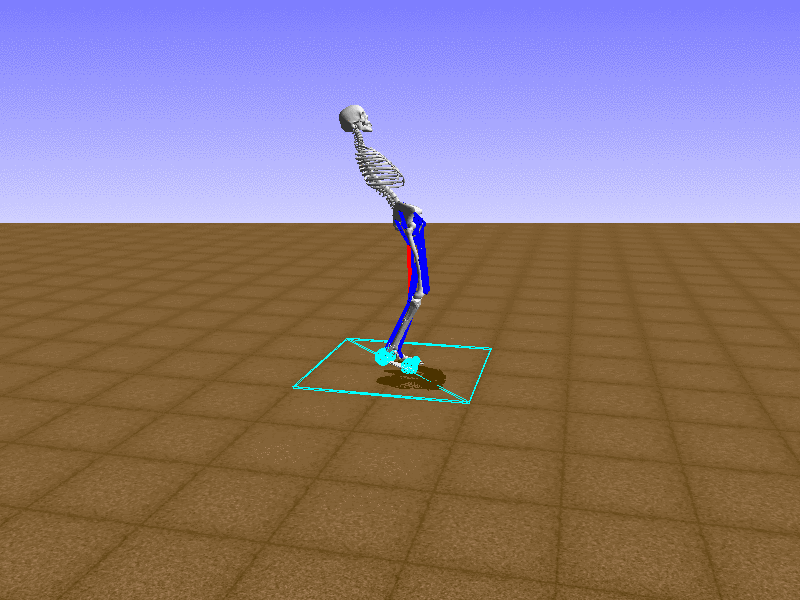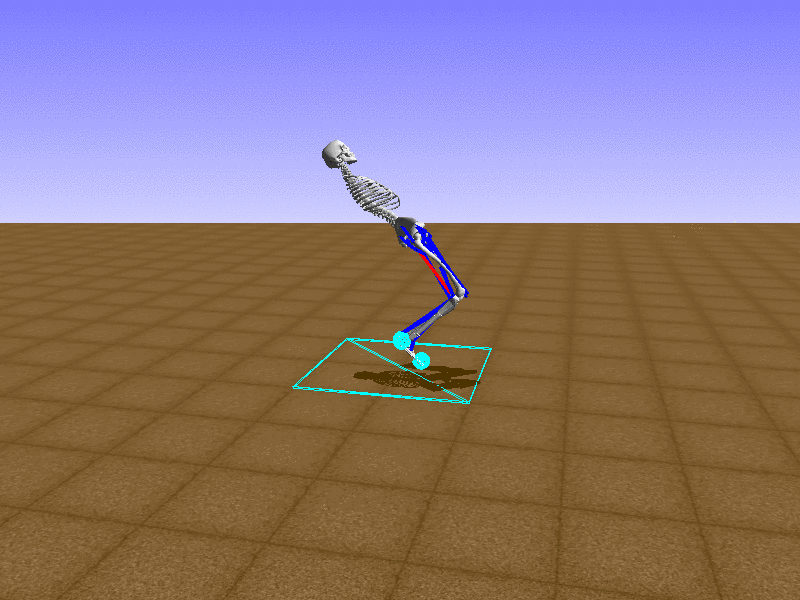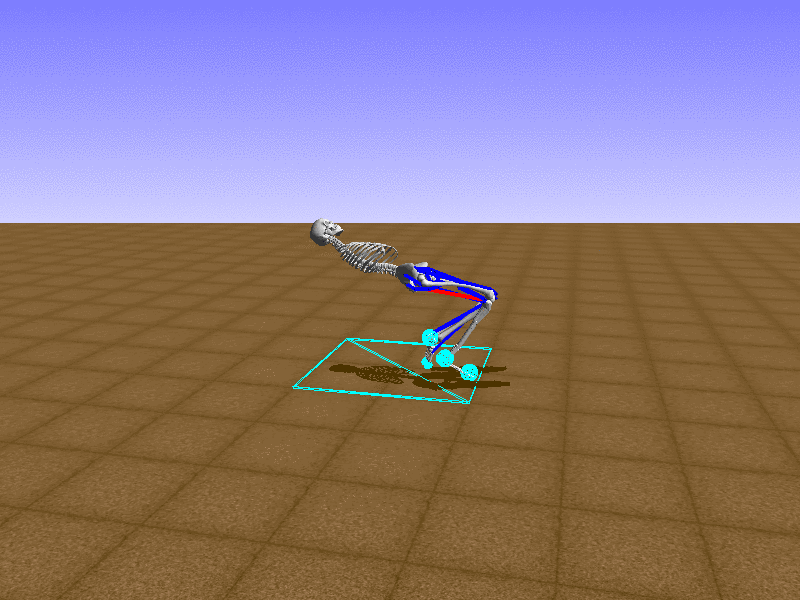
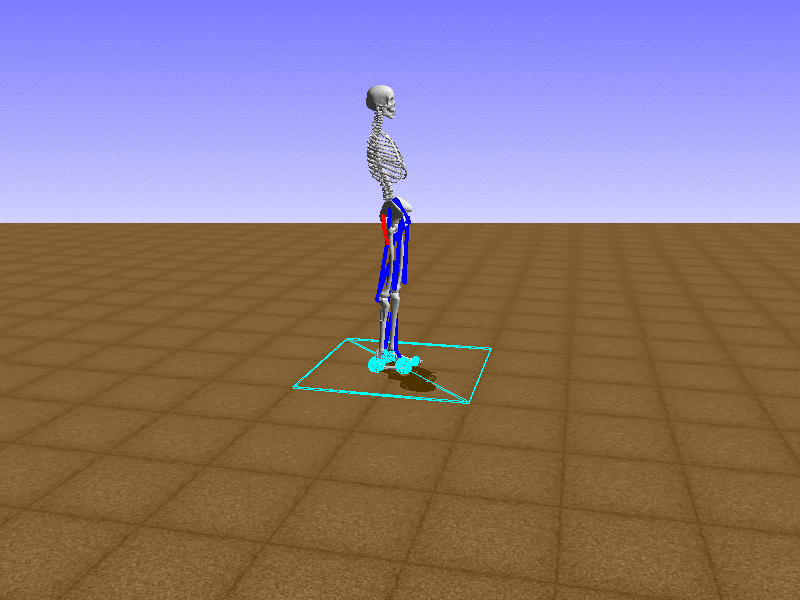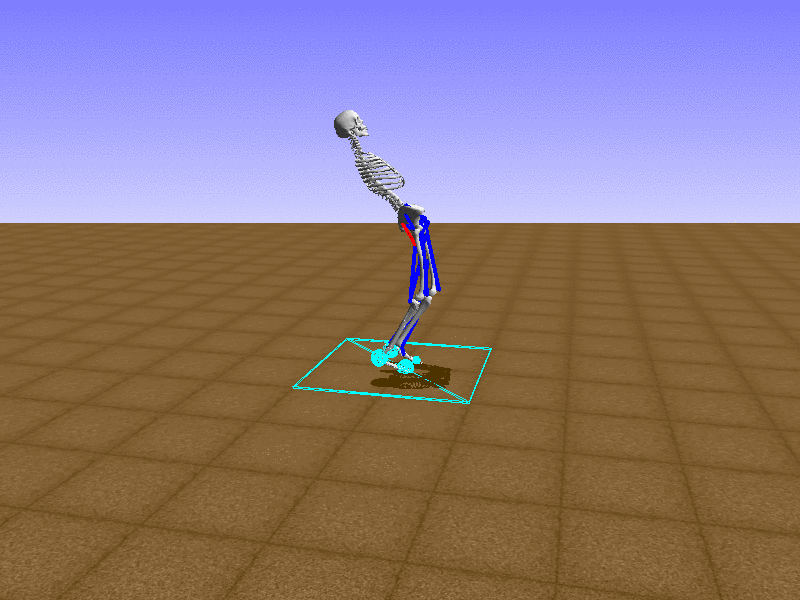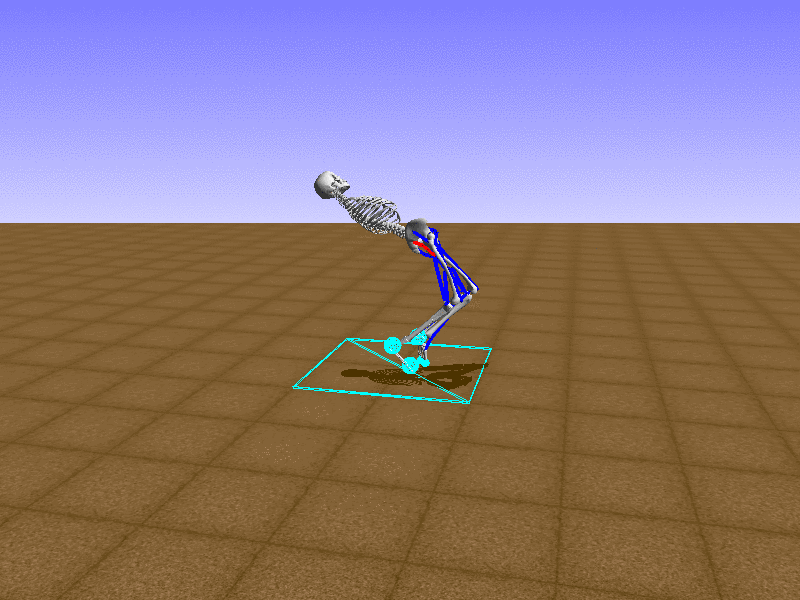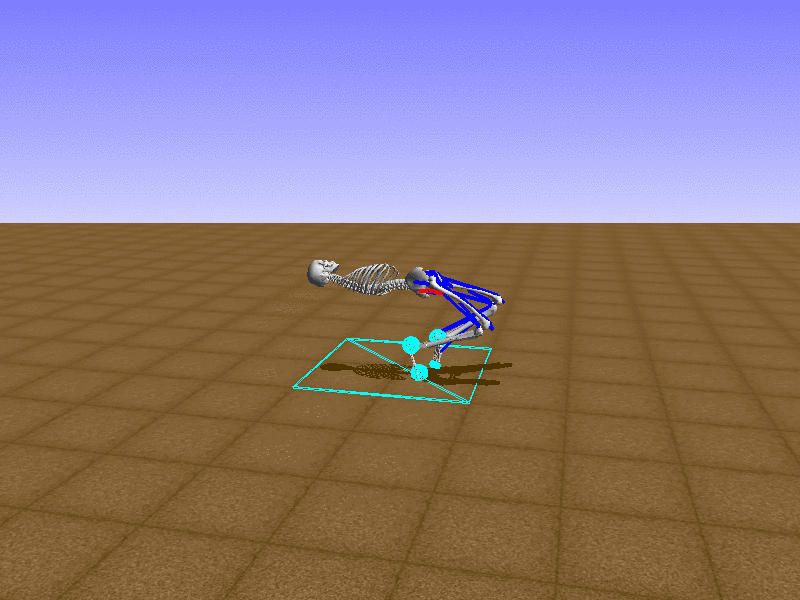
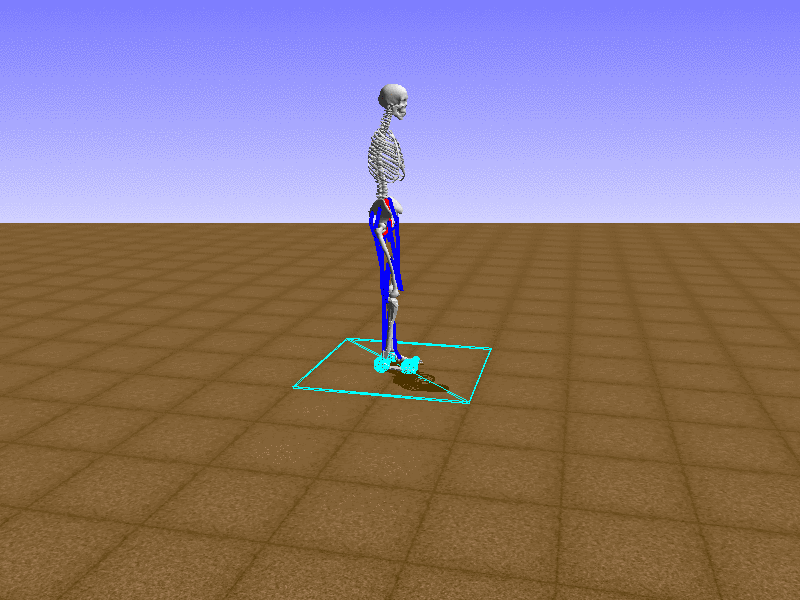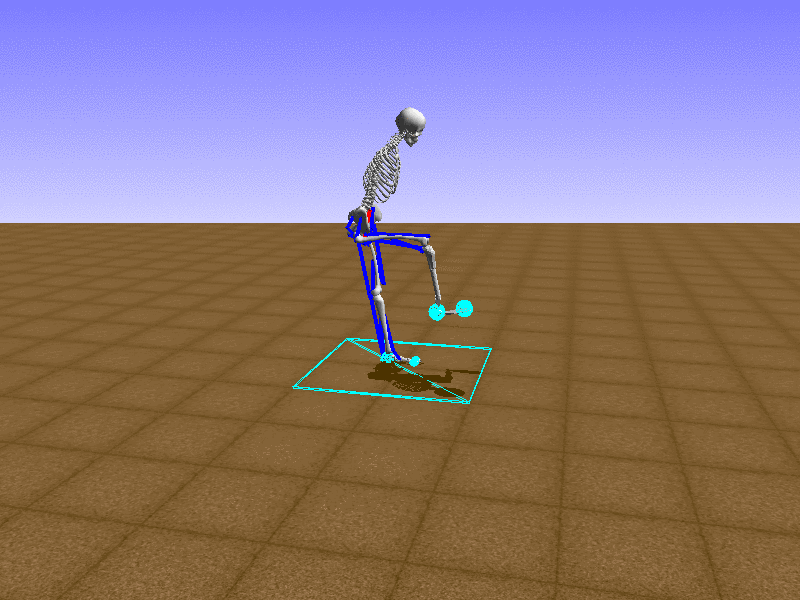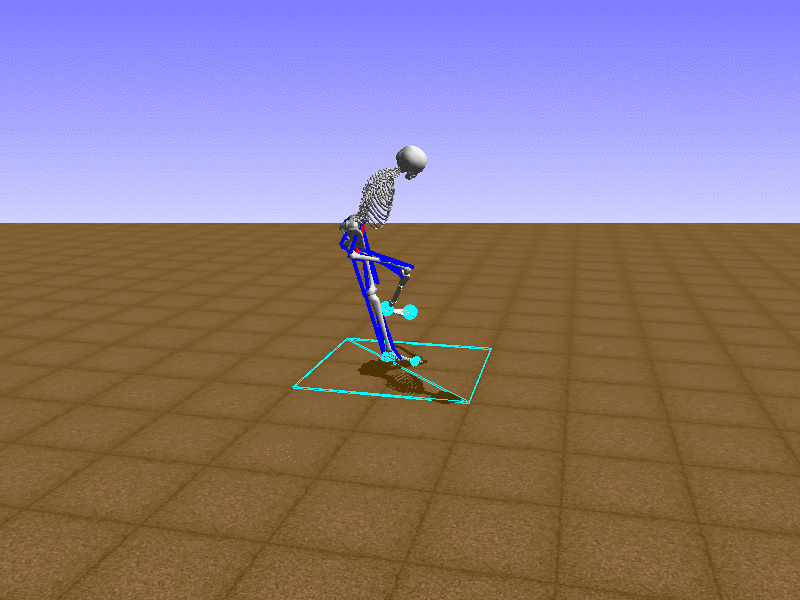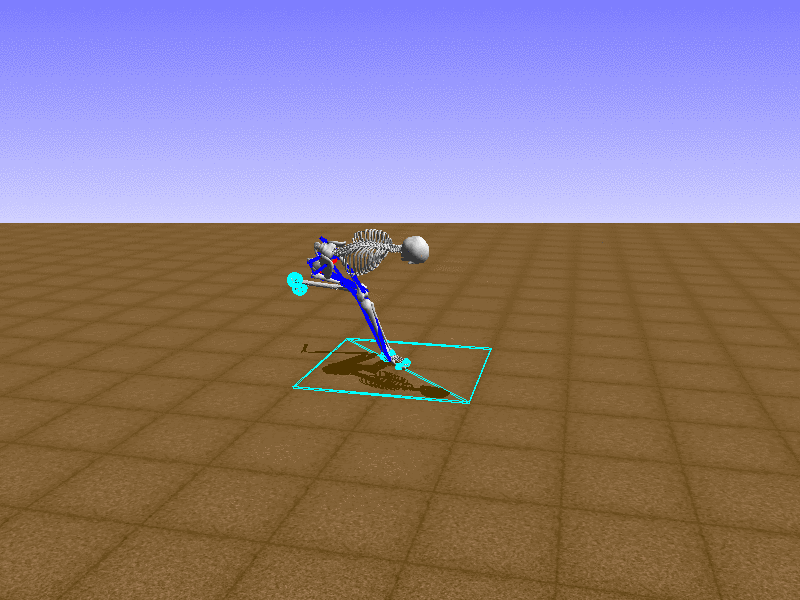
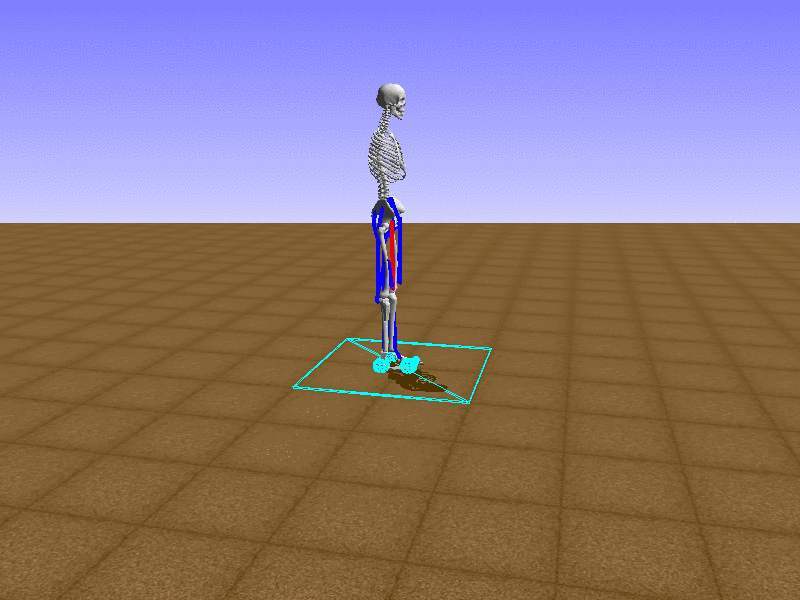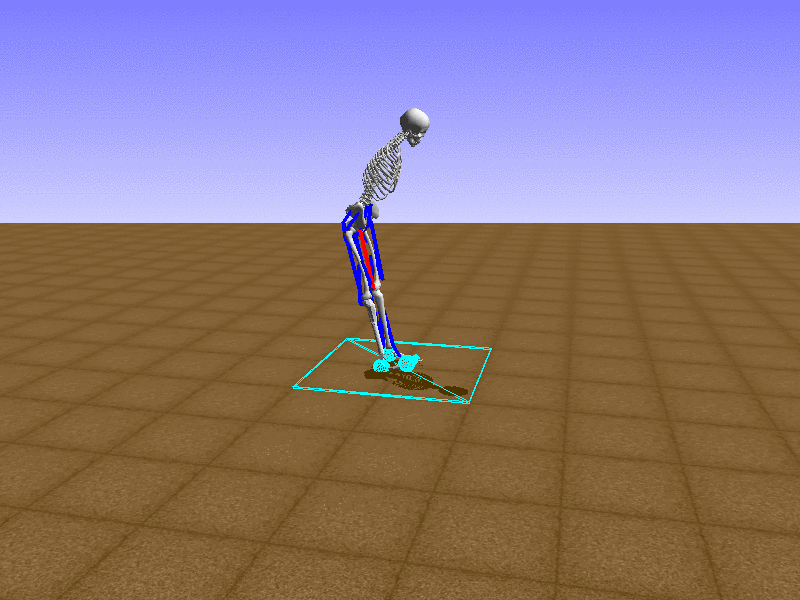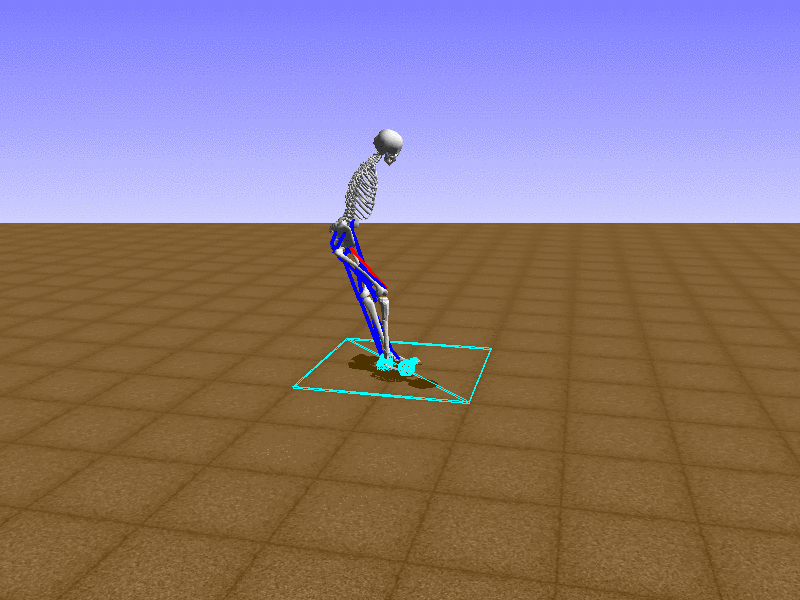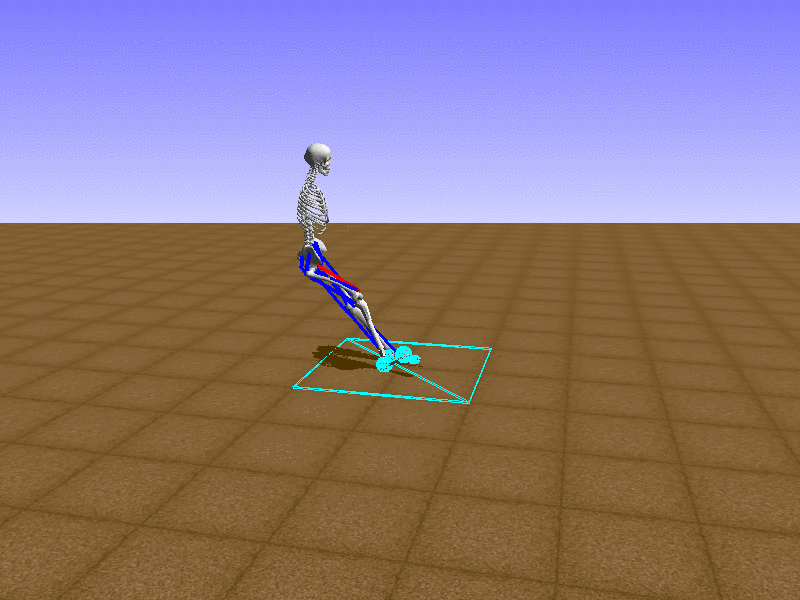
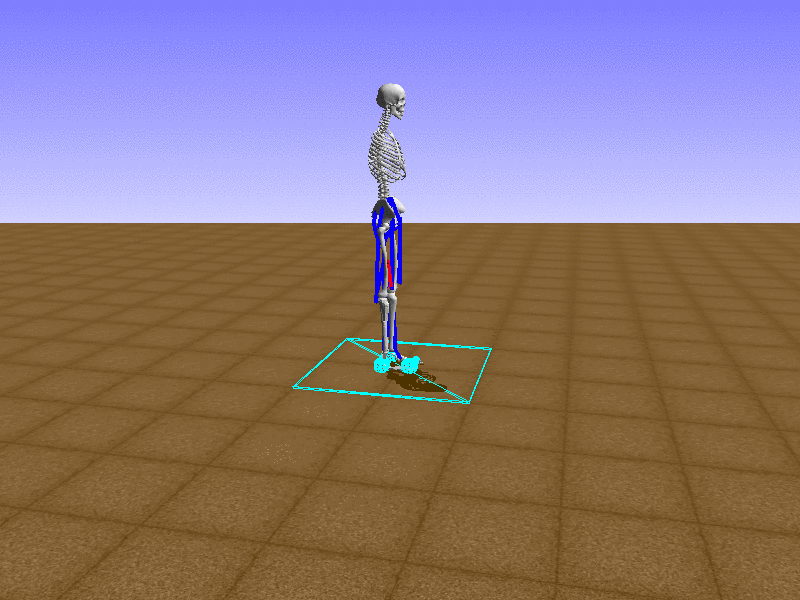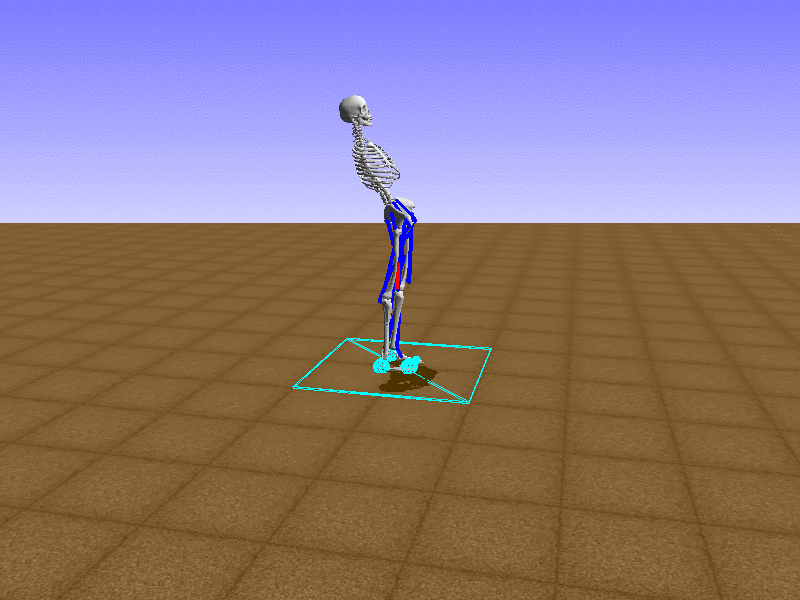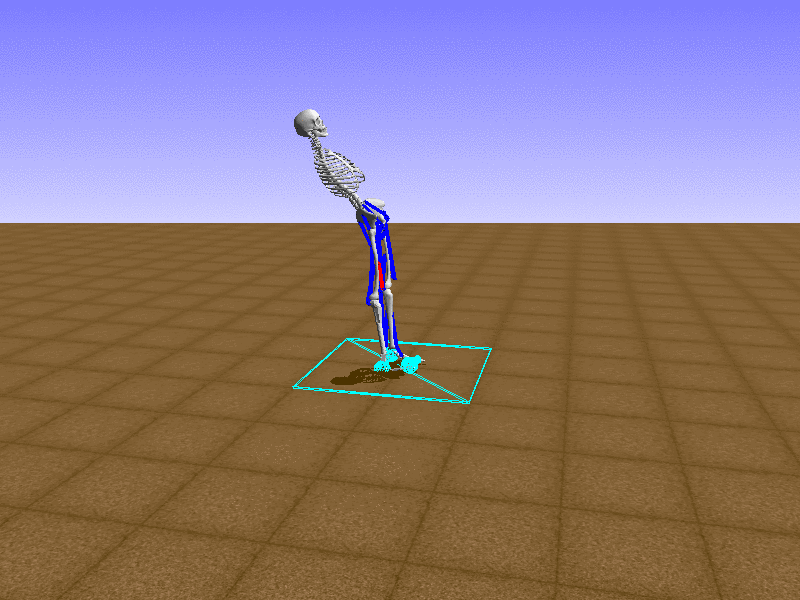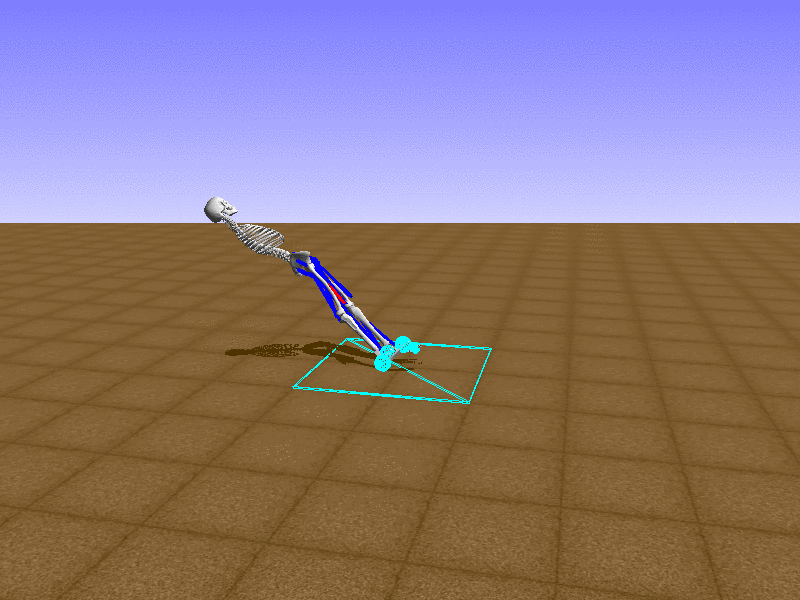
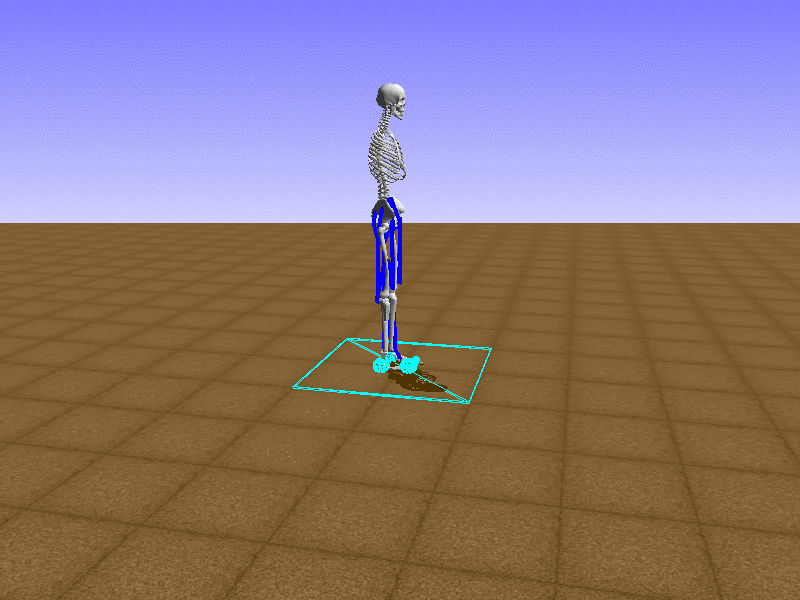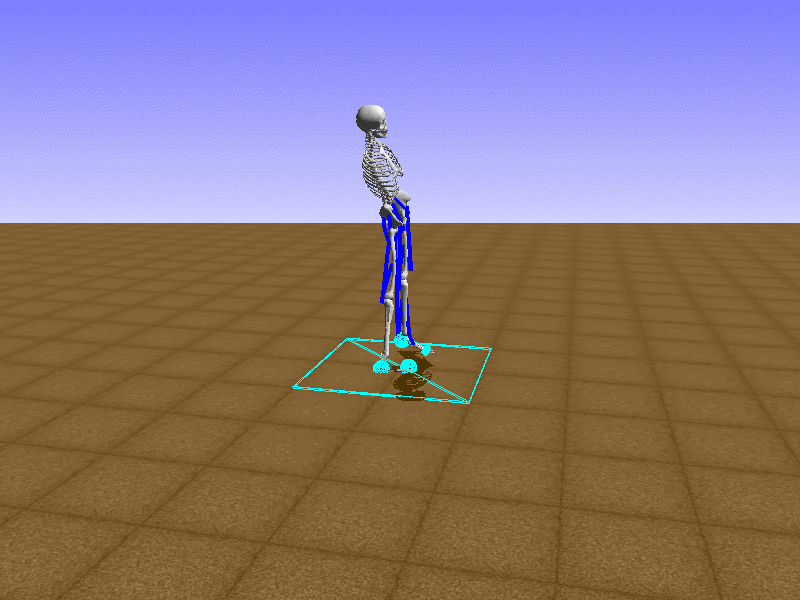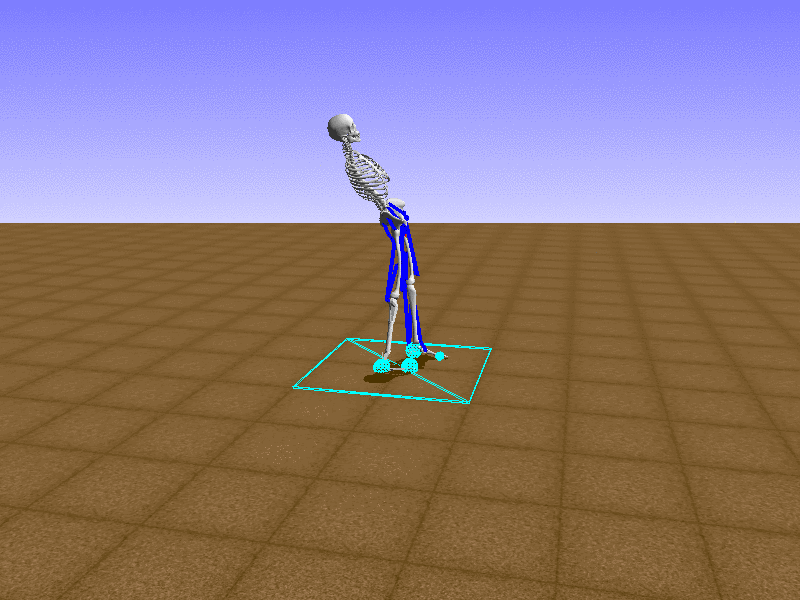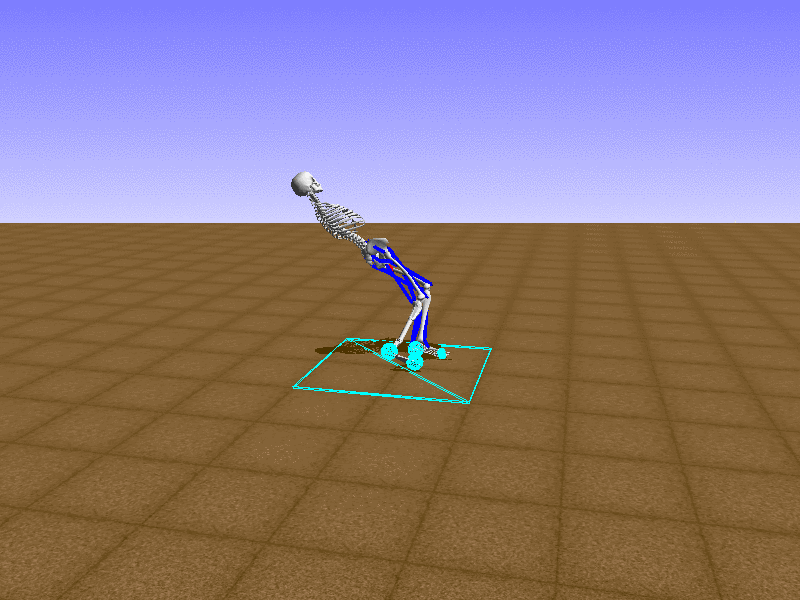
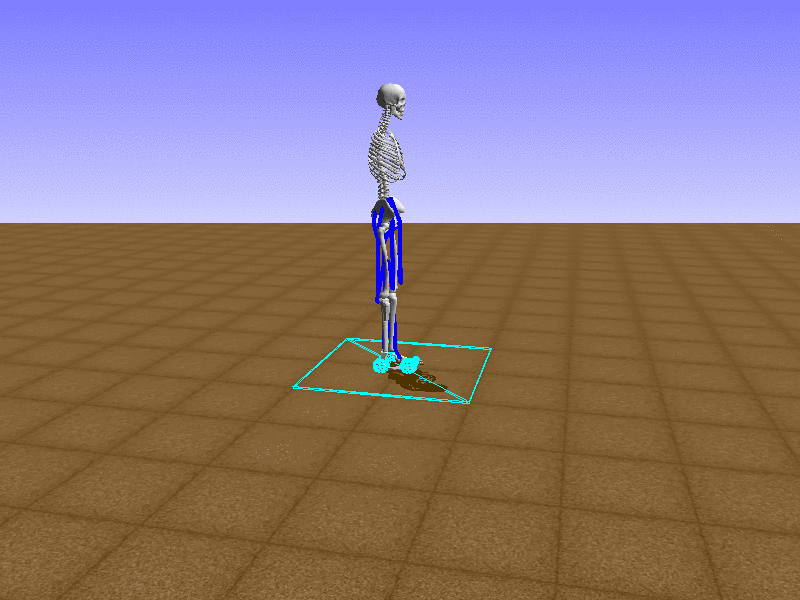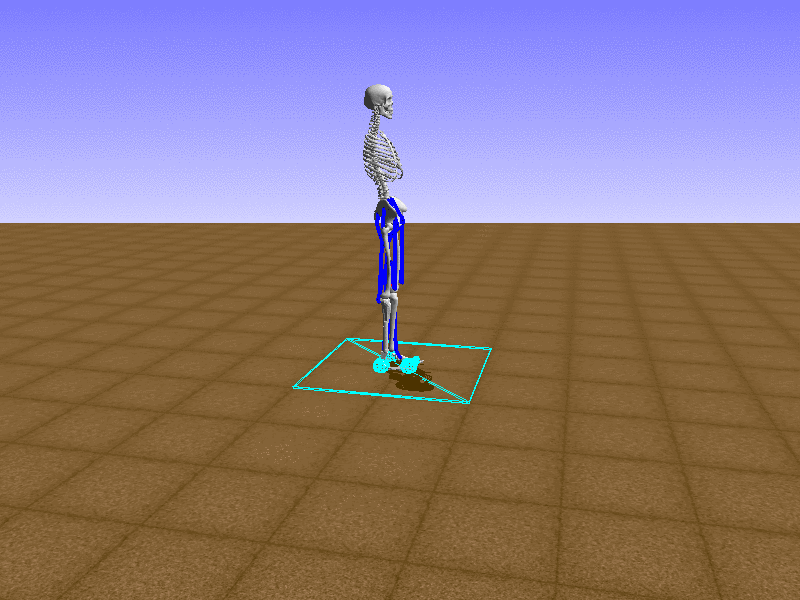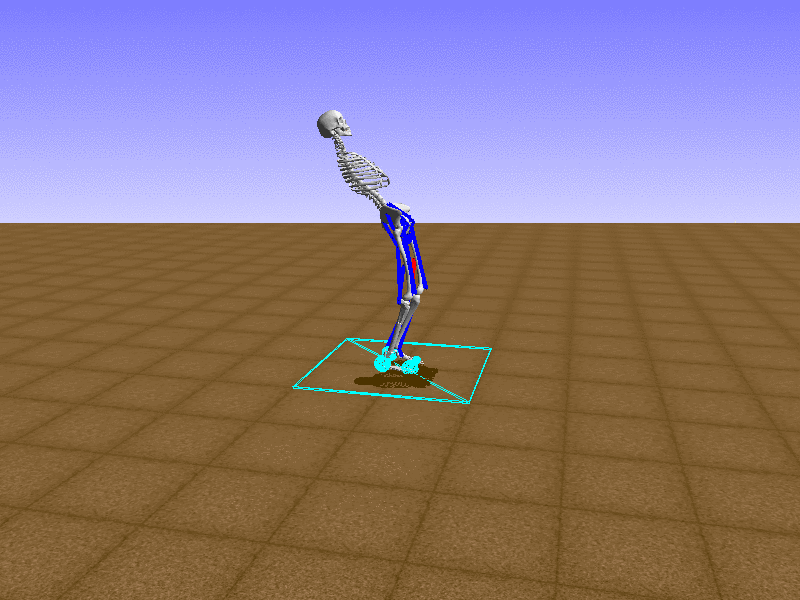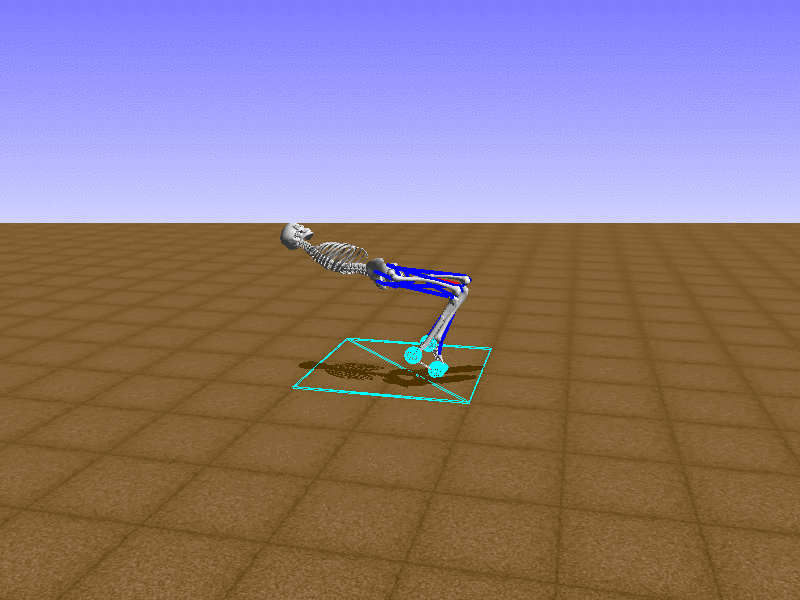
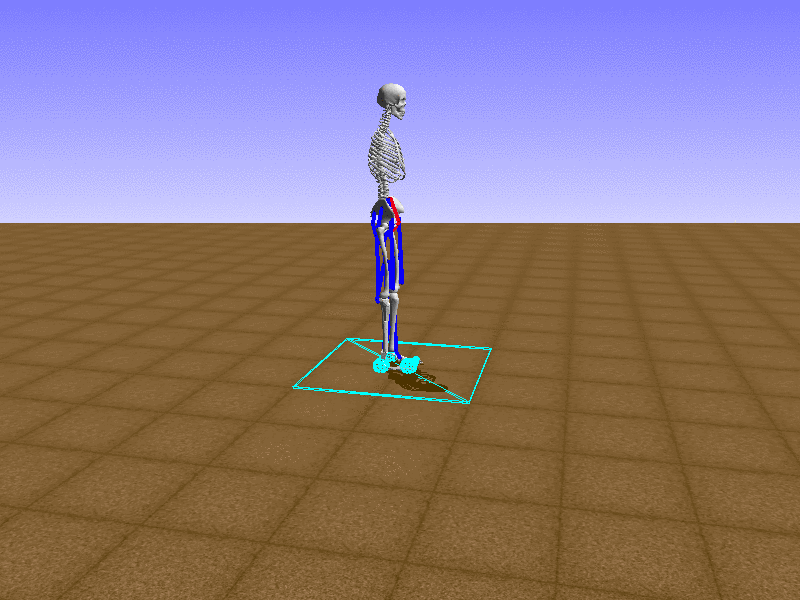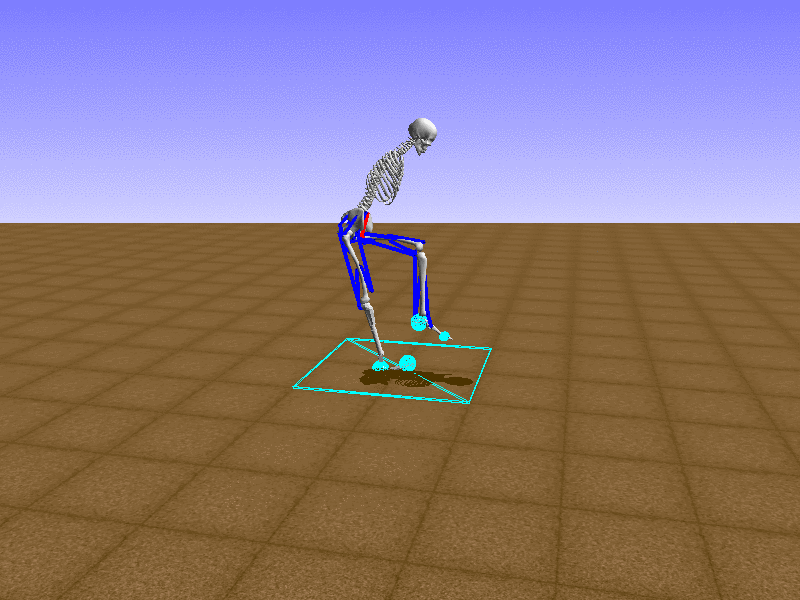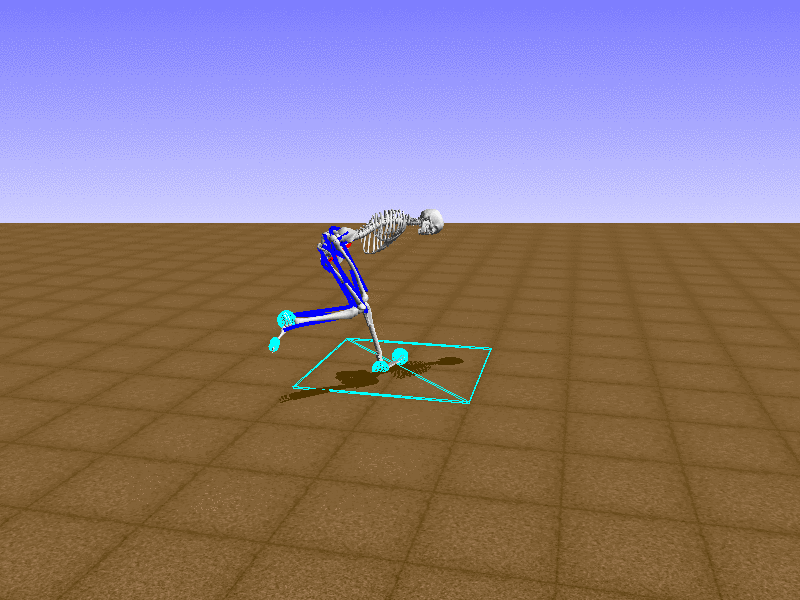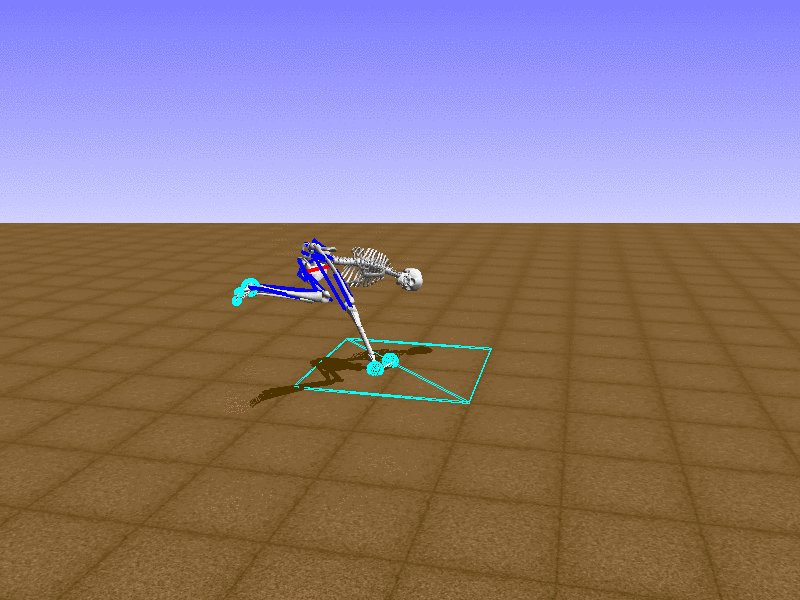
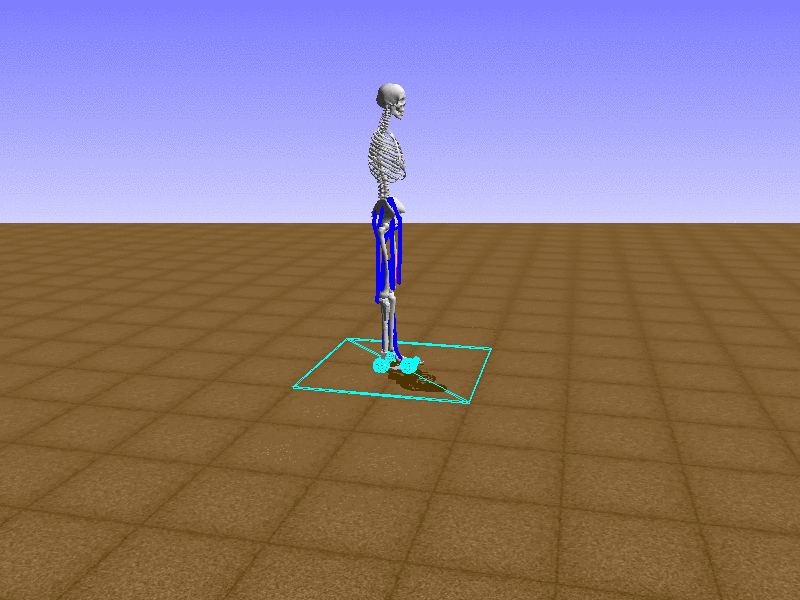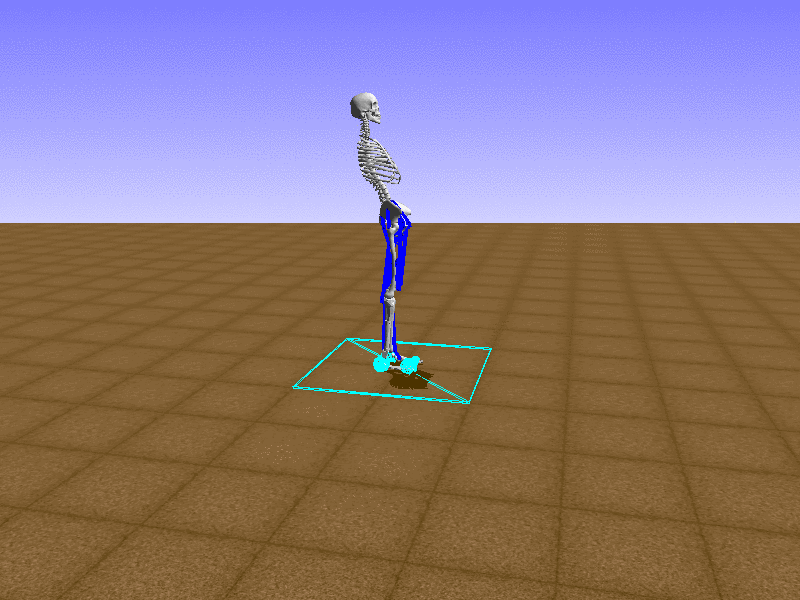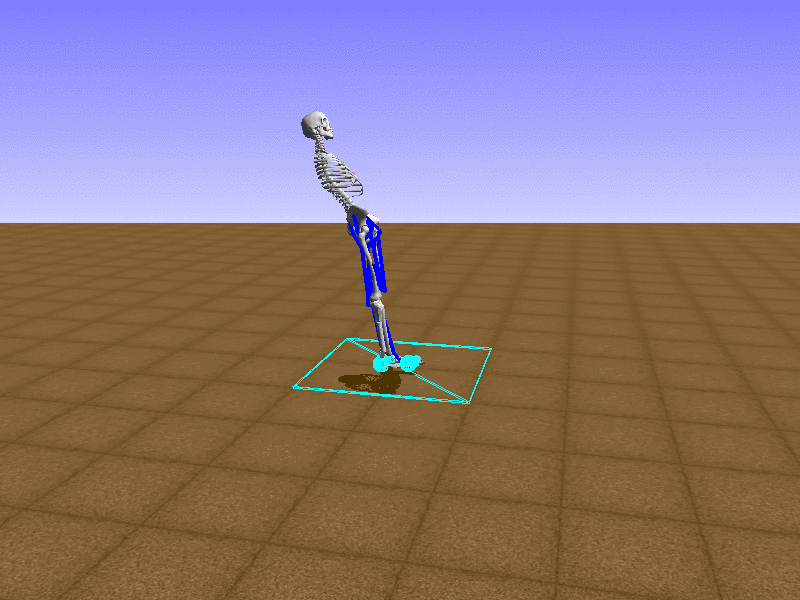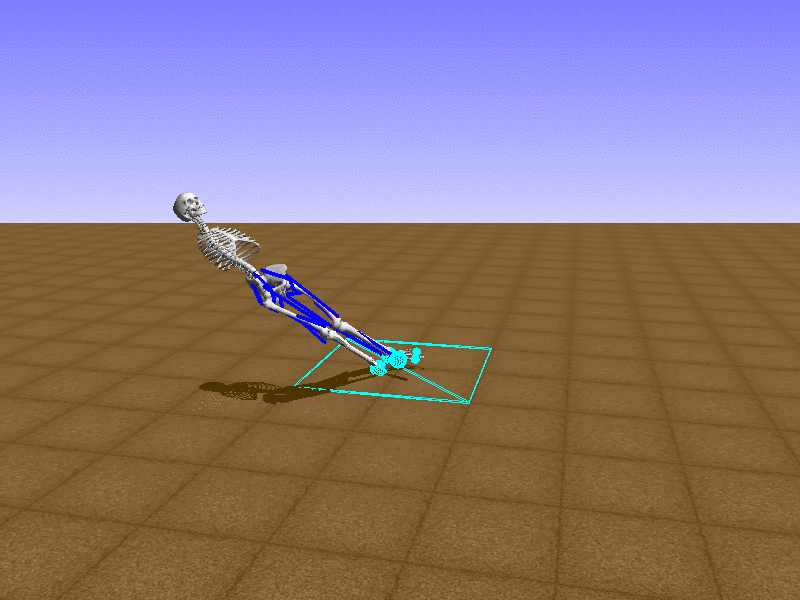
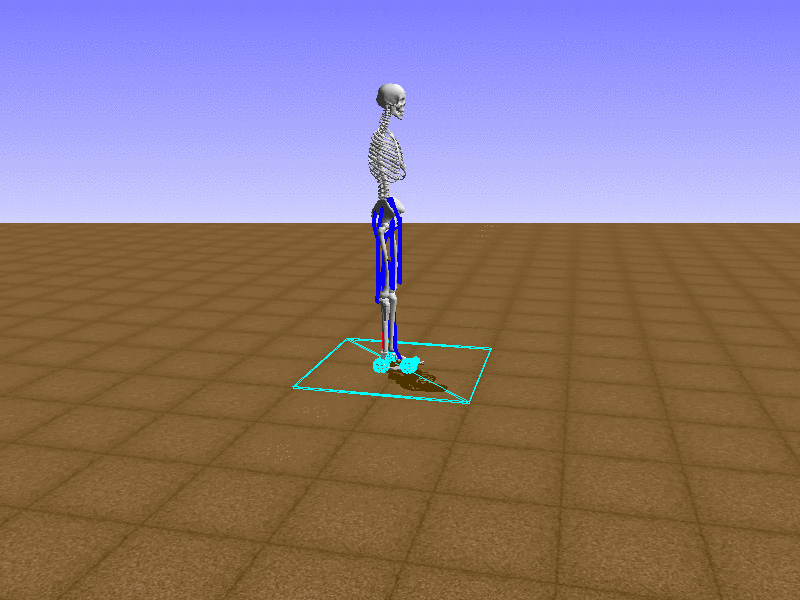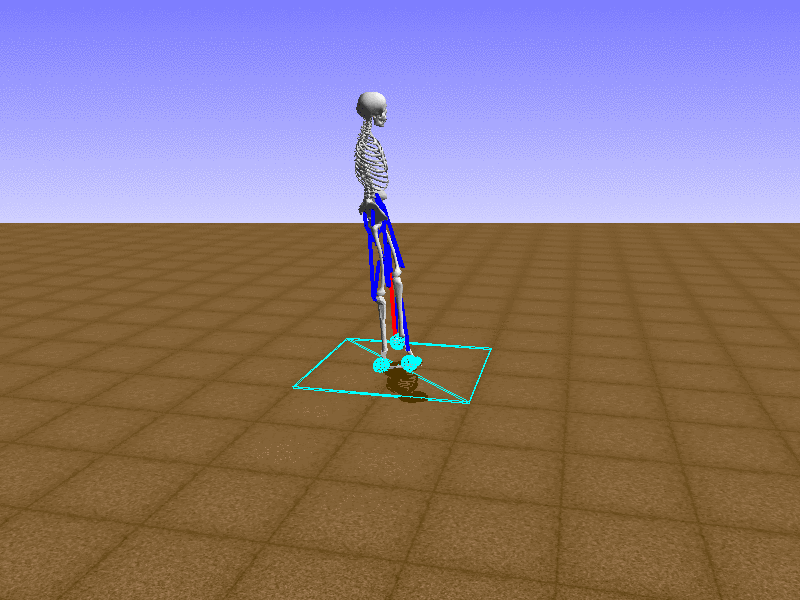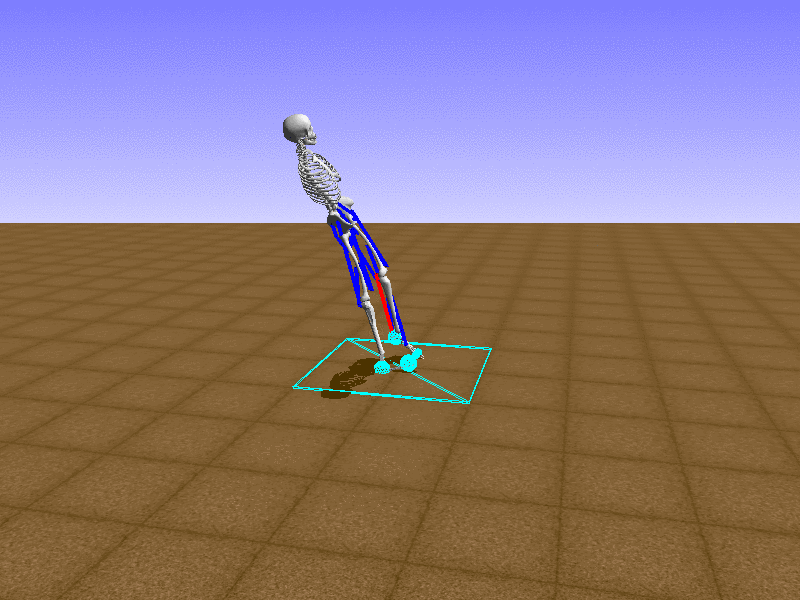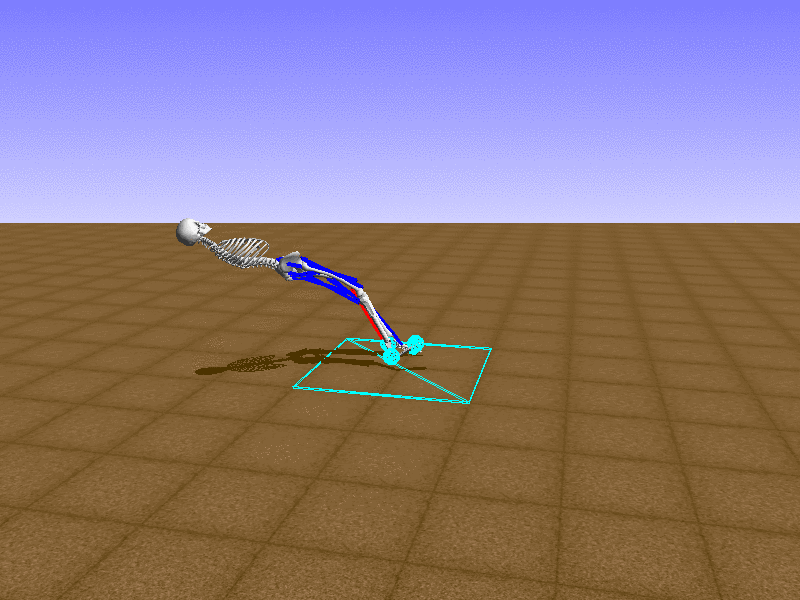
Hip Thrust
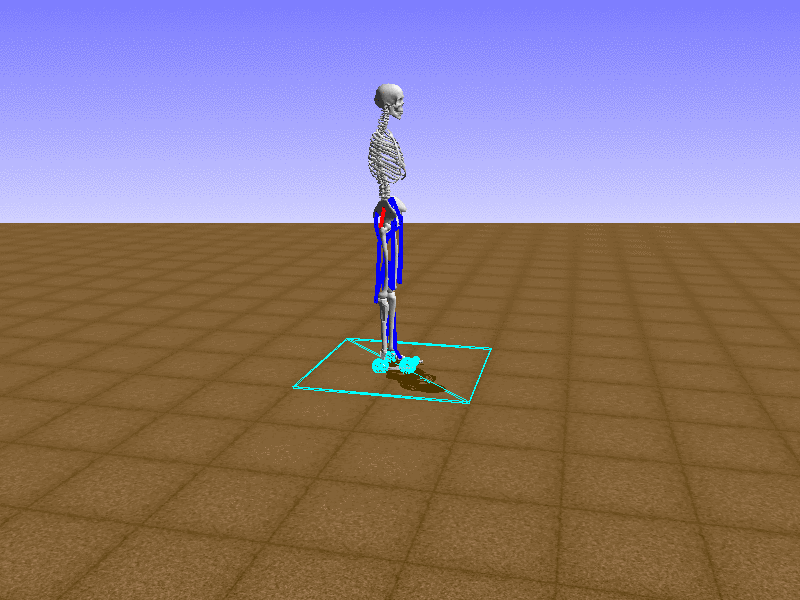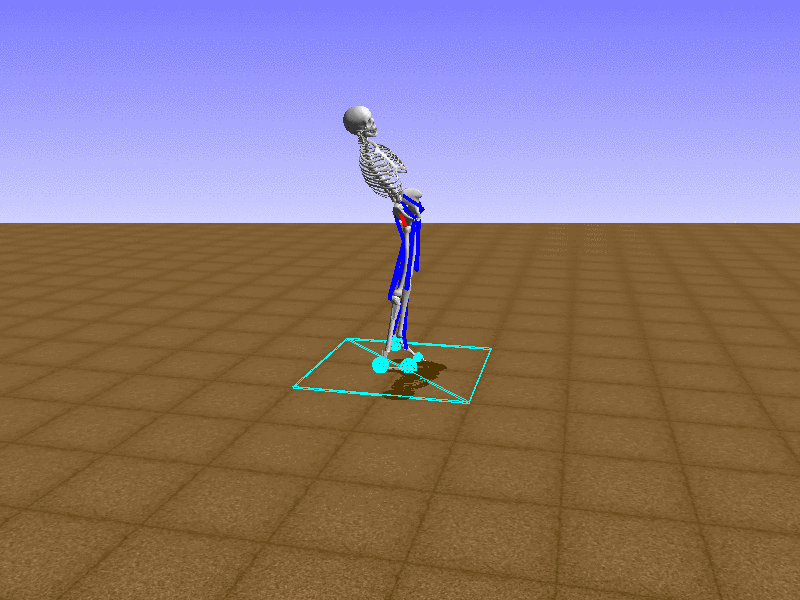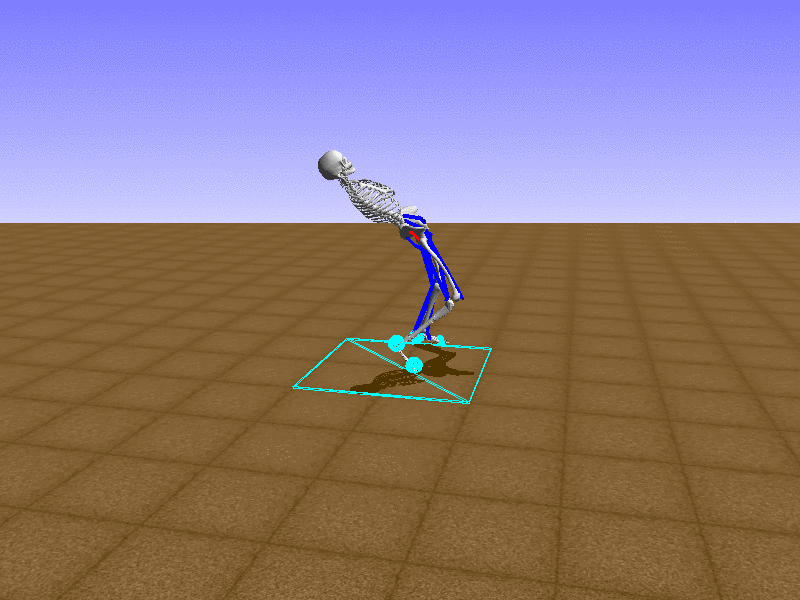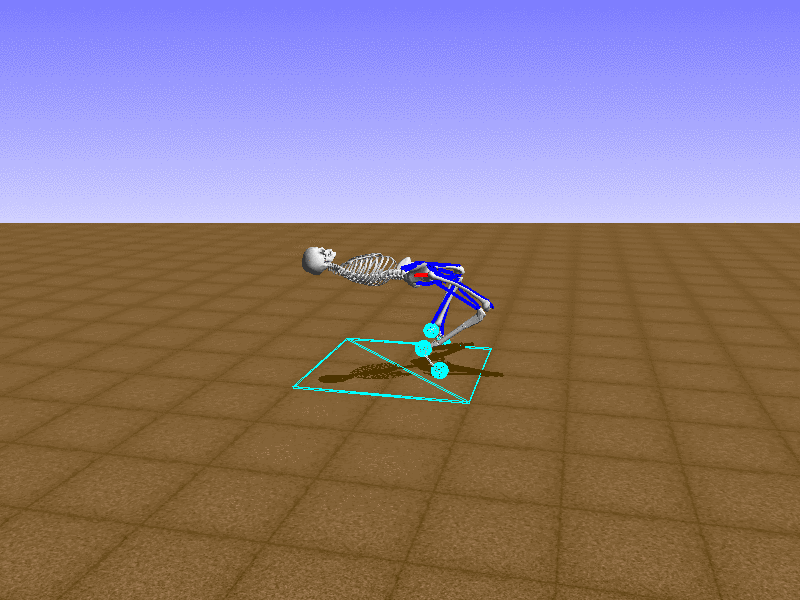
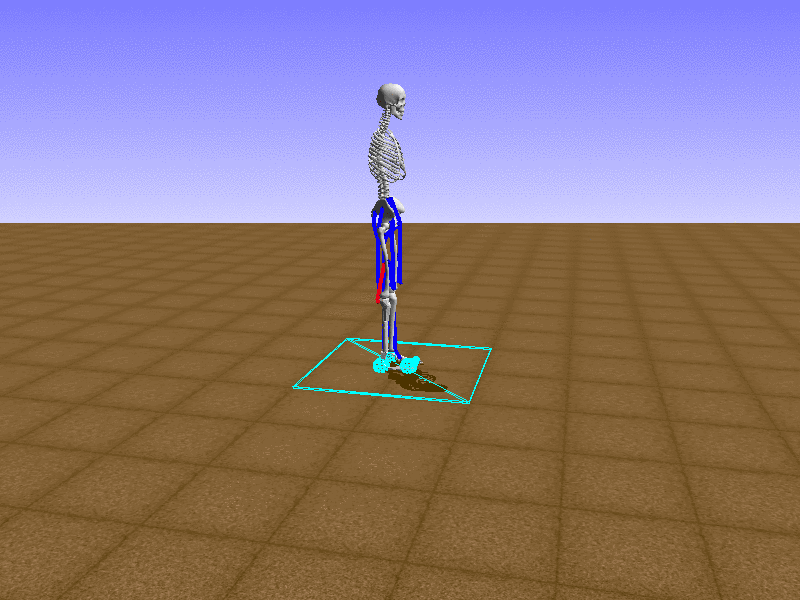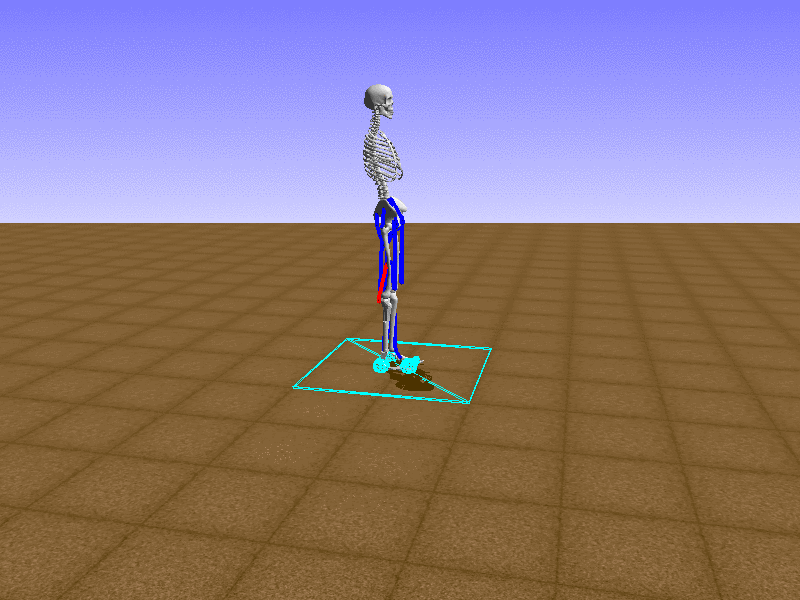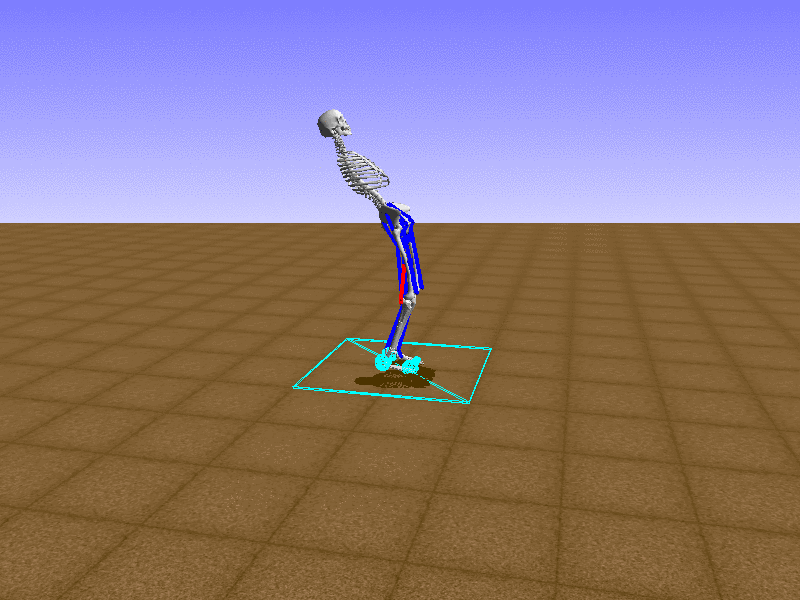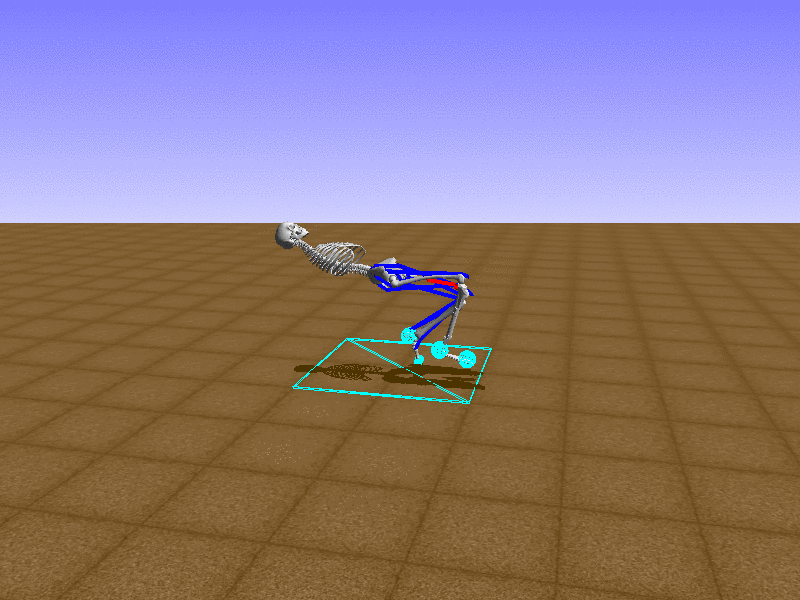
우리의 직감을 확인하기 위해, 허리를 전진시키는 간단한 행동을 숫자를 조합해서 만들어보자. 19개의 근육들 중 2번, 4번, 10번, 12번 근육이 비슷한 작용을 하는 것 같으므로, 이 근육들에 최대한 힘을 주고 (1) 나머지 근육들은 전혀 힘을 주지 않는 (0) 행동을 해보자.
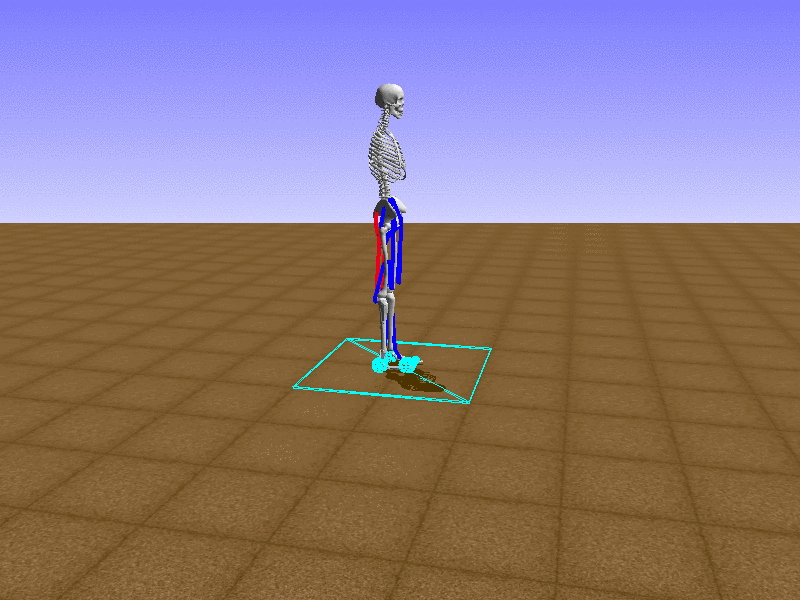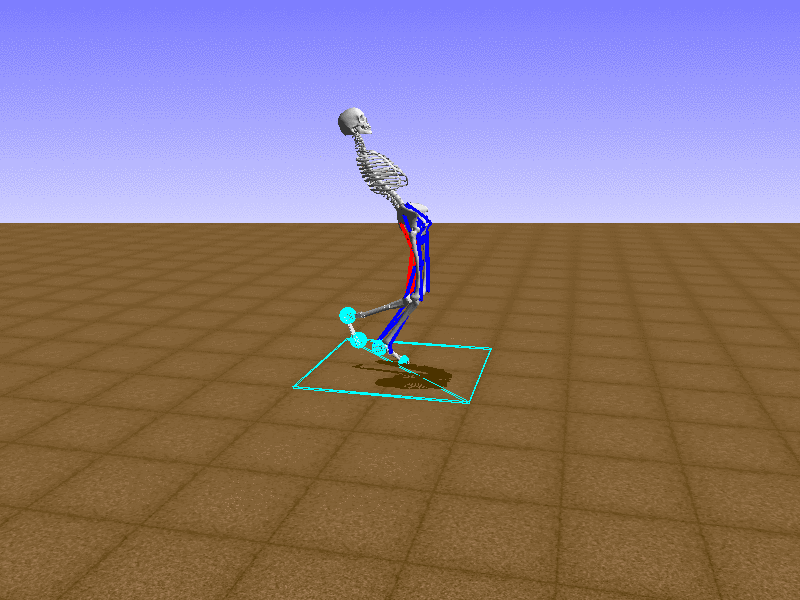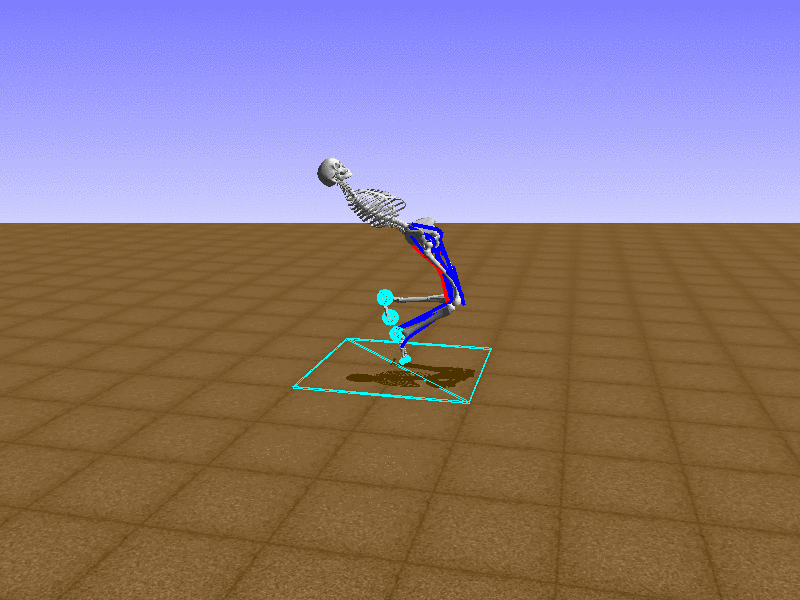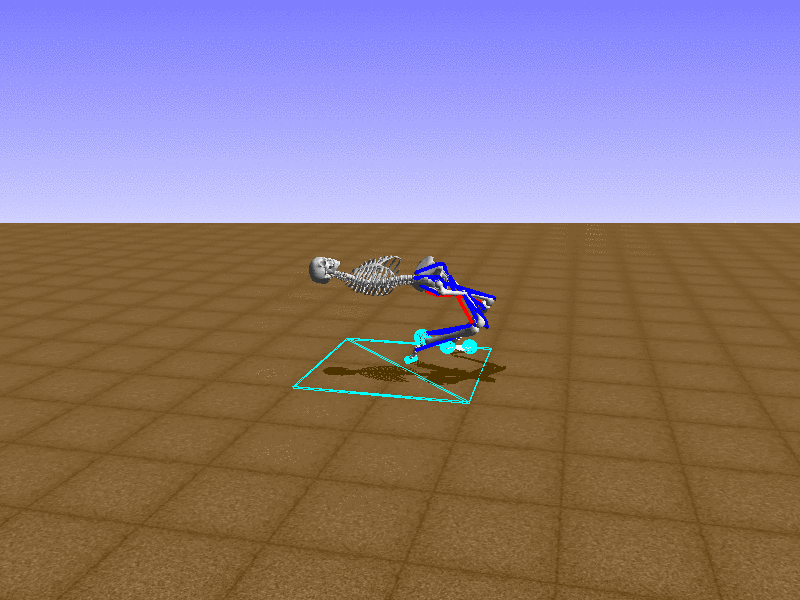
우리가 예상했던 것처럼 허리를 강하게 전진시킨다.
osim-rl-helper
KerasDDPGAgent
KerasDDPGAgent 라는 에이전트가 새롭게 osim-rl-helper repository에 추가되었다. 이 에이전트는 Lillicrap et al. 이 2015년 에 쓴 Deep Deterministic Policy Gradient (DDPG) 알고리즘을 사용한다. 이 에이전트를 학습시키고 실행하거나 제출하려면 우선 keras 와 keras-rl 파이썬 패키지를 설치해야 한다.
conda install keras
pip install keras-rl
KerasDDPGAgent를 실행하고 제출하는 것은 다른 에이전트들과 동일한 방법으로 run.py를 통해 가능하다. KerasDDPGAgent를 학습시키고 싶다면, 학습하고 싶은 타임스텝의 개수를 -t/--train 플래그로 주면 된다. 예를 들어, 아래의 커맨드는 에이전트를 1000의 타임스텝동안 학습시킨다.
./run.py KerasDDPGAgent --train 1000
훈련이 끝난 후 KerasDDPGAgent 는 KerasDDPGAgent_actor.h5f 와 KerasDDPGAgent_critic.h5f라는 파일들을 생성하거나, 이미 존재한다면 업데이트한다. 이 파일들은 학습된 actor와 critic 인공신경망을 저장한 파일들이다. KerasDDPGAgent를 실행하거나 제출할 때 이 두 파일들을 불러오므로, 훈련을 하지 않은 경우 실행하거나 제출할 수 없다.
KerasDDPGAgent는 KerasAgent라는 클래스를 상속하며, 이 KerasAgent는 train(), test(), submit() 함수를 정의한다. KerasDDPGAgent와 KerasAgent의 코드는 각각 /helper/baselines/keras/KerasDDPGAgent.py 과 /helper/templates/KerasAgent.py 에서 확인할 수 있다.
Client Wrappers
keras-rl 패키지의 에이전트들은 env 라는 환경 파라미터가 필요한다. 로컬에서 실행시킬 때는 상관이 없지만, 제출할 때에는 이 파라미터가 문제가 된다. 에이전트를 제출해서 평가할 때는 클라이언트와 대화해서 클라이언트의 환경을 사용하는데, 클라이언트의 env를 직접 가져오지 않고 클라이언트를 통하기 때문이다. 그러므로, 이 클라이언트를 env 처럼 만들기 위해서는 wrapper가 필요하다. ClientToEnv wrapper는 단순히 client 인스턴스를 env 형태로 만든다.
class ClientToEnv:
def __init__(self, client):
"""
Reformats client environment to a local environment format.
"""
self.reset = client.env_reset
self.step = client.env_step
클라이언트는 observation을 무조건 dictionary 형태로 반환하므로, DictToList wrapper는 이 dictionary 형태를 list 형태로 반환해준다. 이 것은 ProstheticsEnv.get_observation()의 코드를 이용해서 project=True를 한 것과 동일한 결과를 준다.
class DictToList:
def __init__(self, env):
"""
Formats Dictionary-type observation to List-type observation.
"""
self.env = env
def reset(self):
state_desc = self.env.reset()
return self._get_observation(state_desc)
def step(self, action):
state_desc, reward, done, info = self.env.step(action)
return [self._get_observation(state_desc), reward, done, info]
# _get_observation() omitted
마지막으로, 클라이언트와 대화할 때에는 NumPy 타입의 숫자나 배열을 쓸 수 없는데, 이것은 이러한 타입들은 JSON형태로 바꿀 수 없기 때문이다. (서버에 데이터를 보낼 때 JSON 형태로 보낸다) 그래서 NumPy 타입의 action을 파이썬 타입으로 자동으로 변환시키는 JSONable wrapper 를 만들었다.
class JSONable:
def __init__(self, env):
"""
Converts NumPy ndarray type actions to list.
"""
self.env = env
self.reset = self.env.reset
def step(self, action):
if type(action) == np.ndarray:
return self.env.step(action.tolist())
else:
return self.env.step(action)
이 wrapper 들은 /helper/wrappers/ 폴더에서 확인할 수 있다.
다음 주 예정
고맙게도 이 대회의 주최자인 Łukasz Kidziński (@kidzik)가 observation의 각각의 숫자의 의미를 알려주는 페이지를 작성해 주었다. 다음 주에는 이 페이지의 정보를 이용해서 observation space에 대해서 좀 더 자세히 살펴보고, 이 observation을 모니터링해 보려 한다.
현재의 환경에서 에이전트는 local optima (극값)에 빠질 확률이 높다. 이 환경에서 reward (보상)은 pelvis의 포지션에 의해 결정되므로, reward를 많이 받는 가장 쉬운 방법은 위와 같은 허리를 강하게 전진시키는 행동을 취하는 것이다. 하지만 이러한 행동은 에이전트의 균형을 무너뜨려서 곧 쓰러지게 한다. 이 문제를 해결하는 한 방법은 reward를 바꾸는 것이다. 작년에 Learning to Run 대회에 참가한 Adam Stelmasczczyk가 자신이 어떻게 reward를 바꿔보았는지 자신의 포스트에 설명했는데, 후에 이 포스트대로 reward를 바꿔보려 한다.