시리즈
- 1주차: 대회 이해하기
- 2주차: Action Space 이해하기
- 3-4주차: Observation Space 이해하기
- 5주차: Reward 이해하기
- 6-8주차: 강화학습 실전 기술
최근 동향
nskiran (#1), rl_agent (#3), ymmoy999 (#4), Firework (#6), Yongjin (#8), HP (#9), jack@NAN (#10) 이 새로운 에이전트로 10위 안으로 들어섰다. 리더보드에 대한 자세한 내용은 다음 섹션을 참고하자.
1라운드와 2라운드에 관해서 혼란이 생겼는데, 정리하자면 1라운드는 9월 16일까지 진행되고, 끝나면 2라운드가 9월 30일까지 진행될 예정이라고 한다. 1라운드는 에이전트가 3 m/s 의 고정된 속도로 달리는 것이 목표고, 2라운드에서는 이 속도가 시간에 따라 바뀔 수 있는데, 어떻게 바뀌는지 등의 정보는 곧 공개될 것이라고 한다.
또, AI for Prosthetics 팀이 Google Cloud Platform의 스폰서를 받게 된 것을 축하한다. 8월 15일까지 리더보드에 0 이상의 점수가 등록된 1~400위의 팀들은 250불 상당의 GCP 크레딧을 제공받을 것이다. 현재 리더보드에 50명 정도의 사람밖에 없고, 34명만이 0 이상의 점수를 가지고 있으니, 많은 사람들이 참여해서 크레딧을 받기 바란다.
리더보드
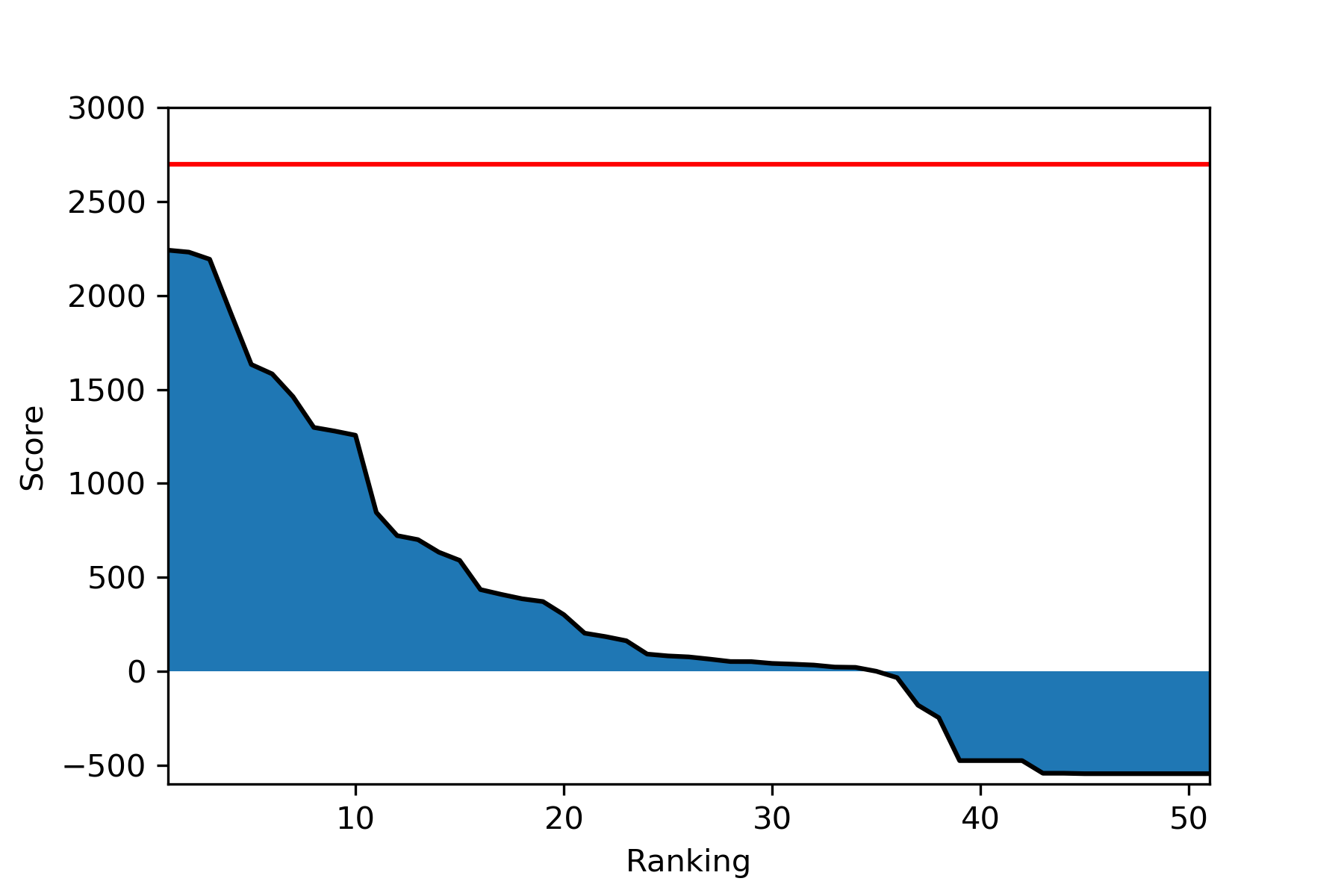
이번 주에 많은 사람들이 에이전트를 제출해서, 상위권에서 큰 지각변동이 일어났다. 그로 인해 Mattias_Ljungström을 제외한 모든 자리는 새로운 에이전트로 채워진 상태이다. 참고로, 현재 최상위권의 10명 중 6명만 지난해의 Learning to Run 대회에 참여했으므로, 처음 이 대회를 접하는 사람들도 도전하면 충분히 좋은 결과를 얻을 수 있을 것이다.
| 참가자 | 점수 (총 보상) | 마지막 제출 시간 (UTC) |
|---|---|---|
| nskiran | 2240.904 | Mon, 23 Jul 2018 05:25 |
| lijun | 2230.505 | Mon, 16 Jul 2018 09:03 |
| rl_agent | 2192.552 | Thu, 26 Jul 2018 07:51 |
| ymmoy999 | 1910.049 | Wed, 25 Jul 2018 13:03 |
| Mattias_Ljungström | 1632.521 | Wed, 11 Jul 2018 15:30 |
| Firework | 1582.416 | Fri, 20 Jul 2018 03:04 |
| aadilh | 1461.556 | Mon, 16 Jul 2018 00:02 |
| Yongjin | 1297.568 | Wed, 25 Jul 2018 00:03 |
| HP | 1278.196 | Tue, 24 Jul 2018 13:48 |
| jack@NAN | 1255.956 | Fri, 27 Jul 2018 05:26 |
Reward
강화학습의 목표는 reward signal (보상 신호)로 정의된다. 에이전트의 목표는 한 에피소드에서 총 reward를 최대화하는 것이다. 어떻게 보면, 보상은 환경 중 에이전트에게 가장 중요한 부분이다. 에이전트가 state (상태) 나 action (행동) 의 value (가치) 에 대해 잘 몰라도, 만약 높은 return (총 보상) 을 꾸준히 받는다면, 그 에이전트는 좋은 에이전트이기 때문이다.
Reward 계산법
1라운드에서 에이전트는 3 m/s의 고정된 속도로 뛰어야 하는데, 이 목표는 reward가 계산되는 방식에 그대로 나타난다.
여기서 $v$는 pelvis (엉덩이)의 $x$ 축 속도이다. 즉,
reward = 9 - abs(3 - obs['body_vel']['pelvis'][0]) ** 2
그러므로, 만약 $\mid 3 - v_t \mid > 3$ 이라면, 그 타임스텝의 보상 $r_t$ 은 음수이다. 저 공식은 너무 빠르게 뛰거나 ($v_t > 3$) 속도가 음수일 때 ($v_t < 0$) 성립된다. 물론, 에피소드가 끝나면, 어떠한 보상도 받을 수 없다.
이제 1미터를 가는 두 가지 방법을 비교해보자. 한 방법은 100스텝 (1초) 동안 1 m/s의 속도로 가는 것이고, 다른 한 방법은 33스텝동안 (0.33초) 동안 3 m/s의 속도로 가는 것이다. 문제를 간단하게 하기 위해, 이 스텝들 동안 받는 보상이 에이전트가 받는 유일한 보상이라 가정하자. 그렇다면 첫 방법의 return은
그에 비해, 두 번째 방법의 return 은
생각 외로, 두 방법의 return에는 큰 차이가 있다. 물론, 두 번째 방법의 속도를 유지할 수 있다면 2700이라는 최고 점수를 획득할 수 있으므로 당연히 두 번째 방법이 더 좋다. 하지만, 이러한 policy가 에피소드가 이르게 끝나게 한다면, 천천히 reward 를 모으는 궁극적으로 더 높은 return 을 가져올 수 있다.
Reward 수정
최근, 강화학습 쪽에서 reward 를 수정해서 좋은 결과를 이룬 논문들이 많이 발표되었다. 그 중 특히 유명한 논문들은 Playing hard exploration games by watching YouTube 와 RUDDER: Return Decomposition for Delayed Rewards 로, 아타리 2600 게임인 Montezuma’s Revenge 와 Bowling 등의 게임을 환경으로 이용하였다. 이 두 게임은 sparse rewards 가 특징이라서, 좋은 action 과 나쁜 action을 구별하기 위해 에이전트가 오랫동안 환경을 explore 해야하는 어려움이 있다. 이러한 게임에서는 위의 YouTube나 RUDDER 같은 reward를 바꾸는 방법들이 현재 가장 높은 점수를 받은 State of the Art (SotA) 이다. (Bowling SotA, Montezuma’s Revenge SotA).
이 대회의 환경은 이와 달리 매 스텝에 보상이 나오는 dense reward를 가지고 있어서, 굳이 보상을 수정하지 않아도 에이전트를 훈련시킬 수 있다. 하지만, 그렇다고 수정할 수 없다는 것은 아닌다. Imitation Learning (DQfD, YouTube)나 RUDDER 같은 복잡한 방법은 쓰지 않아도 되겠지만, 좀 더 나은 보상을 줄 수 있다면, 에이전트가 학습하는데 분명히 도움이 될 것이다.
하지만, 이러한 접근 방식이 약간 위험하다는 것을 이해하고 있어야 한다. Reward를 수정하므로써 우리는 우리가 가진 prior 정보를 reward에 넣으려는 것이다. 보통, Reward 는 에이전트에게 목표가 무엇인지만 알려주고, 어떻게 그 목표를 이룰 것인지 알려줘서는 안 된다. 이러한 정보를 주기에 알맞은 곳은 value function 이나 policy 을 초기에 설정할때의 값이다. (Suttton and Barto, 2018). 이 문제를 해결하는 한 방법은 보상이 수정된 환경에서 에이전트를 학습시킨 후, 진짜 환경에서 다시 학습시키는 것이다.
Reward를 어떻게 수정해야 할지 아마 확신이 서지 않을 것이다. 그럴 때는 잘 학습된 에이전트와 그렇지 않은 에이전트들을 비교해서, 어떤 점에서 차이가 나는지를 보면 도움이 될 수 있다. 아래는 nskiran, lijun, 그리고 rl_agent 의 에이전트로, 각각 2240.904, 2230.505, and 2192.552의 높은 점수를 받았다.
다음은 700~800점대의 점수를 받은 세 개의 에이전트들이다.
마지막으로, 150~400의 낮은 점수를 받은 세 개의 에이전트들이다.
살아남기
위에서 볼 수 있듯이, 높은 점수를 얻는 에이전트들은 공통적으로 오랫동안 살아남는다. 어찌보면 당연한 것이, 2000대의 점수를 받기 위해서는 적어도 222스텝이 필요하기 때문이다. 그러므로, 에이전트를 처음 학습할 대 살아남는 것만 신경쓰도록 학습하는 것도 좋은 방법이다. 이러한 목표는 아주 간단한 reward로 표현할 수 있다/
이 reward는 짧은 에피소드를 원하는 미로찾기 등의 에이전트와 정반대이다.
곧은 자세
그렇다면, 에피소드가 어떻게 끝나는지 보자. 공식적으로 300스텝이 끝나거나 엉덩이가 0.6 미터보다 밑으로 떨어지게 되면 에피소드가 끝나는데, 위의 에이전트들을 보면 대부분의 에이전트는 윗몸이 크게 흔들리는 것 때문에 300스텝 전에 에피소드가 끝나게 된다. 그러므로, 에이전트가 윗몸을 고정시키도록 보상을 바꿀 수 있다. 하지만, 최상위권의 에이전트들 또한 윗몸을 꽤 흔드는데, 아마 의족이 있어서 모델이 기본적으로 균형이 맞지 않기 때문에 그런 듯 하다. 그러므로, 윗몸을 흔드는 것의 경계선이 명확하지 않아서, 이 방식을 사용하려면 미세한 조정들이 필요할 것이다.
이 방식은 작년 대회에서 쓰였던 Lean Forward (윗몸 앞으로 기대기) 방식과 어느 정도 비슷하다. 저번 대회에서는 옆으로 넘어질 수 없었고, 모델 또한 대칭적이라서, 윗몸의 위치는 몸 앞이나 뒤가 될 수 밖에 없는데, 당연히 윗몸이 몸 약간 앞에 있는 것이 뛰기에 적합한 자세이기 때문에, 많은 참가자들이 이러한 행동을 촉진시키도록 reward를 수정하였다.
osim-rl-helper
osim-rl-helper 패키지를 이용하는 유저들이 좀 더 좋은 경험을 할 수 있게 에이전트들과 환경 wrapper들을 일관되게 바꾸었다. 만약 osim-rl-helper를 쓴다면, 제출 전에 자기 컴퓨터에서 테스트를 해보자!
TensorforcePPOAgent
Schulman et al. (2017) 이 발명한 Proximal Policy Optimization 방법을 쓰는 에이전트를 추가했다. 작년 대회의 대부분의 최상위권 에이전트들은 DDPG나 PPO 방법을 썼으니까, 둘 다 사용해 보는 것을 추천한다. 이 에이전트를 튜닝하는 가장 쉬운 방법은 인공 신경망의 구조를 바꾸거나, 다른 optimizer (Adam, RMSProp 등) 를 쓰는 것이다.
다음 주 예정
이 포스트를 마지막으로, 환경에 대해 설명하는 것은 마무리가 되었다. 이번 주는 이제 작년 대회의 최상위권 에이전트들을 분석하고 학습시켜서 비교해볼 생각이다. 또, keras-rl 패키지가 느리기 때문에, osim-rl-helper 에 더 빠른 DDPG 에이전트를 추가할 예정이다.